V hurhaji okolo GDPR (pozri jeho navtipnejšie závery), zanikla jedna podstatná informácia. Regulácia o ochrane osobných dát podstatne rozširuje právo jednotlivca na vysvetlenie rozhodnutia. Hoci v tejto oblasti GDPR zatiaľ nezavádza rovnako “mastné” pokuty ako pri nesprávnom nakladaní s našimi údajmi, do budúcna ide o ešte dôležitejší krok ako to, či ste dali na spracovanie údajov súhlas. Táto téma dokonca patrí medzi TOP 15 trendov v dátovej analytike pre rok 2018.
Od Adama …
Čo vlastne teda je Právo na vysvetlenie? Ak akýkoľvek obchodný alebo servisný proces používa automatické rozhodovacie systémy, každému človeku, ktorý je predmetom takéhoto rozhodnutia, vzniká v EU právo na vysvetlenie, na základe akých kritérií sa presne stroj rozhodol. Hoci toto právo bolo prvý krát formulované už v roku 1995 (verili by ste tomu?), aktuálna GDPR smernica ho výrazne posilňuje. Je to zjavne aj preto, že s nástupom AI sa počty autonómnych procesov rozhodnutia začínajú rapídne zvyšovať. Ak pracujete v oblasti analýzy dát, zrejme si však položíte otázku: Je však táto norma v praxi vykonateľná?
 Väčšina bežných rozhodovacích procesov vo firmách a v štátnej správe, ktoré sa rozhodujú automatizovaným spôsobom, vznikli ako Machine Learning modely. (Viac na túto tému sme písali tu.) Pri nich nie je komplikované popísať rozhodovanie, pretože či už ide o Rozhodovacie stromy, Regresie alebo SVM modely, skladbu a významnosť jednotlivých faktorov, ktoré sa podieľali na rozhodnutí detailné poznáme. Situcia sa začína výrazne komplikovať pri Random Forest modeloch, kde síce poznáme zoznam faktorov, ktoré do rozhodnutia vstupovali, ale ich konkrétny vplyv už popísať ťažšie. Ten istý faktor môže jednom z sub-modelov mať pozitívny vplyv na rozhodnutie a vzápätí v inom sub-modeli korigovať mieru vplyvu presne opačnou koreláciou s celkovým hodnotením. Človeku by sme teda vedeli povedať, že fakt, že má aj kreditnú kartu výrazne ovplyvnil schvaľovanie jeho hypotéky. Ale či to bol v konečnom dôsledku podporný alebo problémový činiteľ, už nie je tak jednoznačné.
Väčšina bežných rozhodovacích procesov vo firmách a v štátnej správe, ktoré sa rozhodujú automatizovaným spôsobom, vznikli ako Machine Learning modely. (Viac na túto tému sme písali tu.) Pri nich nie je komplikované popísať rozhodovanie, pretože či už ide o Rozhodovacie stromy, Regresie alebo SVM modely, skladbu a významnosť jednotlivých faktorov, ktoré sa podieľali na rozhodnutí detailné poznáme. Situcia sa začína výrazne komplikovať pri Random Forest modeloch, kde síce poznáme zoznam faktorov, ktoré do rozhodnutia vstupovali, ale ich konkrétny vplyv už popísať ťažšie. Ten istý faktor môže jednom z sub-modelov mať pozitívny vplyv na rozhodnutie a vzápätí v inom sub-modeli korigovať mieru vplyvu presne opačnou koreláciou s celkovým hodnotením. Človeku by sme teda vedeli povedať, že fakt, že má aj kreditnú kartu výrazne ovplyvnil schvaľovanie jeho hypotéky. Ale či to bol v konečnom dôsledku podporný alebo problémový činiteľ, už nie je tak jednoznačné.
Situácia sa úplne vymkne z medzí jednoduchého vysvetlenia pri prechode do Deep Learningu. Modely umelej inteligencie postavené na neurónových sieťach sú vo väčšine prípadov neinterpretovateľné spôsobom zrozumiteľným pre bežného človeka. Systém vrstiev, v ktorých každej z nich prichádza k transformácií, vzájomnej kombinácii a prehodnoteniu významnosti jednotlivých vstupných údajov, často môže zabrať niekoľko desiatok strán na popísanie rozhodnutia a prejsť si príkladom konkrétneho rozhodnutia o konkrétnom človeku je časovo neúnosné. Ak sa k tomu navyše pridá rozmer, že neurónová sieť je učiaceho sa typu, úloha sa zdá už od základu nesplniteľná. V momente, keď človek namieta rozhodnutie a žiada jeho vysvetlenie totiž systém už môže dávno zvažovať úplne iné faktory ako v jeho prípade. Zároveň všetci vieme, že učiace modely sa zdokonaľujú najmä kvôli historickým chybám (o korekcie ktorých sa snažia spätnou propagáciou chyby). Asi by sa ťažko vysvetľovalo klientovi, že on(a) bol tá chyba, ktorá dopomohla k celkovému vyladeniu modelu.
A predsa sa točí
Nech situácia vyzerá akokoľvek beznádejne, v skutočnosti sa v tejto oblasti dejú zásadné posuny. Existujú totiž oblasti, kde dôvody rozhodnutia sú minimálne tak dôležité ako rozhodnutie samotné. Asi najvypuklejším príkladom je v tomto ohľade Zdravotníctvo. Ide o ľudský život, takže žiadne dobrodružstvá, ktoré zabijú desiatky ľudí, než sa vyladia tu nie sú prípustné. Dokonca ani test, na chorobu ktorý má čo i len 1-2% false positive mieru, nie je prijateľný. Sú totiž aplikované na vysoké počty pacientov a vytvárali by tak veľa zúfalých ľudí. (Uvedomte si, že 1% error rate by spôsobil, že v každom väčšom paneláku by žil niekto v mylnom domnení, že zomiera na rakovinu, či v každej rannej električke by bol jeden s podozrením na AIDS). Práve kvôli týmto oblastiam vznikla XAI, teda EXPLAINABLE AI. Podstatou XAI je nielen dodať kvalitný prediktívny model, ale zlomiť (doposiaľ zastávanú) paradigmu, že ak chcete čo najsilnejšiu predikciu, musíte obetovať interpretovateľnosť modelu a naopak. Aké techniky teda XAI používa?
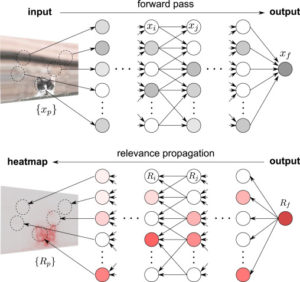
Prvou technikou, ktorú by som vám chcel dať do pozornosti, je Layerwise relevance propagation (LRP), ktorú vo vedeckom článku popísal pre troma rokmi Bach et al. Podstatou tejto metódy je analógia k back-propagation chyby modelu, ktorá však prenáša pomocou váh jednotlivých nodov vo vrstvách významnosť naspäť až na úroveň jednotlivých vstupných informácií v prvej vrstve. V prípade image recognition tak môžete dostať informáciu, ktoré časti obrázka boli pre celkové posúdenie rozhodujúce. S použitím parciálnych derivácií následne dokážu experti zostrojiť aj generickú funkciu, ktorá popisuje model aj vo všeobecnosti. Ak ste v tejto téme zatiaľ nie príliš doma, odporúčam prečítať si toto zhrnutie.
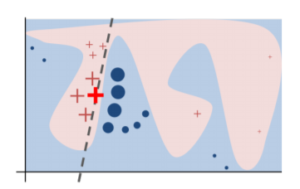
Druhou snubnou metódou XAI, na ktorú som nedávno narazil (cudos aj Banalytics skupine, kde sa táto metóda nedávno mihla), je metóda LIME, ktorú priniesli gentlemani Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin z Washington Univerzity v Seattli, USA. Musím povedať, že LIME si ma naozaj získal, keďže dokáže interpretovať ľubovoľný model, bez ohľadu na jeho architektúru (vyššie spomínané LRP dokáže demystifikovať len neurónové siete, aj to iba určitej architektúry). Je to teda univerzálny “vysvetľovač”, ktorého princíp je zázračne jednoduchý. Na vysvetlenie hraníc oddeľujúcich ÁNO od NIE používa jednoduché lokálne modely, ktoré sú zrozumiteľné aj bežným smrteľníkom. Jedinou nevýhodou LIME je, že dokáže vysvetliť len klasifikačné modely. Keďže však väčšina rozhodovacích procesov sú práve tohto typu, pre Explainable AI je to výrazná pomoc. Pre hĺbavejšie typy prikladám vedecký článok o tejto metóde, pre priamočiarejších čitateľov video samotného autora, ktorý vysvetľuje princíp tohto snubného počinu v XAI.
Ako vidno z oboch citovaných prístupov (zverejnené boli v 2015 a 2016), oblasť XAI je zatiaľ pomerne mladá. Je to o to fascinujúcejšie, že prvé neurónové siete vznikali už pred viac ako 40 rokmi. V každom prípade možno očakávať, že sa s podobnými prístupmi teraz “roztrhne vrece”. Pri prechode od Machine k Deep Learningu, ktorý práve zažívame, totiž “vysvetľovači” budú viac ako nutní. A to aj keď GDPR legislatív zostane k právu na vysvetlenie rovnako vágna ako je tomu aktuálne.
Tento článok je súčasťou širšieho Seriálu o umelej inteligencii. Ak vás téma zaujala, pozrite si aj ostatné diely seriálu.
Publikované dňa 1. 7. 2018.