Aby diskusia o trendoch 2018 v neurónových sietí dávala zmysel, je dôležité, aby sme všetci boli aspoň na podobnej úrovni pochopenia ich podstaty. Tento blog teda berie neurónky od gruntu a vysvetľuje (možno tým menej zasväteným), ako neurónové siete fungujú. Pre skúsenejších deep minerov môžu nasledujúce odseky prísť trochu triviálne.
Miesto pod Slnkom
 Ak by sme si dali dostatočný počet krokov späť a pozreli sa na oblasť dátových analýz (a predpovedí) naozaj zo široka, mohli by neurónové siete “splynúť v dave” s inými formami analytických postupov. Aby sme sa tejto začiatočníckej chybe vyhli hneď na začiatku, začneme tým, že vysvetlíme, čo oprávňuje neurónové siete mať vlastne miesto pod Slnkom. Cieľom neurónových sietí je na základe určitého množstva vstupných informácií dospieť k rozhodnutiu. (napríklad na základe informácií o novom, neznámom človeku rozhodnúť sa, či je chybou pozvať ho/ju na rande). Tento základný mód “daj mi vstupy, poviem Ti ako sa rozhodnúť” majú neurónové siete ešte spoločný s inými typmi data mining algoritmov ako sú rozhodovacie stromy, regresie či support vector machine. (súborne sa nazývajú aj strojové učenie alebo Machine Learning). Tou podstatnou deliacou čiarou je, že zakiaľ každý z postupov Machine Learningu si bude od vás pýtať zoznam kritérií, na základe ktorých chcete aby sa rozhodol, neurónové siete si vypýtajú len hrubé fakty a faktory rozhodovania si už vytvoria sami. Ak by sme to premietli do vyššie zmienenej analógie s rozhodovaním o rande, tak Machine learning (napr. rozhodovací strom) bude chcieť od vás, čo všetko (by) ste vy sami zohľadnili, keď sa rozhodujete medzi viacerými adeptmi na rande (napr. je vtipný, je mi vekom primeraný, máme spoločné hobby, má deti s inou, …). &neurónové siete si dokážu odvodiť takéto faktory rozhodovania, bez toho, že by ste ich museli pomenovať (napr. prídu na to, že muži po 50ke, žijúci na vidieku, veľmi často majú deti s inou. A to vám akosi nepasuje do schémy :).
Ak by sme si dali dostatočný počet krokov späť a pozreli sa na oblasť dátových analýz (a predpovedí) naozaj zo široka, mohli by neurónové siete “splynúť v dave” s inými formami analytických postupov. Aby sme sa tejto začiatočníckej chybe vyhli hneď na začiatku, začneme tým, že vysvetlíme, čo oprávňuje neurónové siete mať vlastne miesto pod Slnkom. Cieľom neurónových sietí je na základe určitého množstva vstupných informácií dospieť k rozhodnutiu. (napríklad na základe informácií o novom, neznámom človeku rozhodnúť sa, či je chybou pozvať ho/ju na rande). Tento základný mód “daj mi vstupy, poviem Ti ako sa rozhodnúť” majú neurónové siete ešte spoločný s inými typmi data mining algoritmov ako sú rozhodovacie stromy, regresie či support vector machine. (súborne sa nazývajú aj strojové učenie alebo Machine Learning). Tou podstatnou deliacou čiarou je, že zakiaľ každý z postupov Machine Learningu si bude od vás pýtať zoznam kritérií, na základe ktorých chcete aby sa rozhodol, neurónové siete si vypýtajú len hrubé fakty a faktory rozhodovania si už vytvoria sami. Ak by sme to premietli do vyššie zmienenej analógie s rozhodovaním o rande, tak Machine learning (napr. rozhodovací strom) bude chcieť od vás, čo všetko (by) ste vy sami zohľadnili, keď sa rozhodujete medzi viacerými adeptmi na rande (napr. je vtipný, je mi vekom primeraný, máme spoločné hobby, má deti s inou, …). &neurónové siete si dokážu odvodiť takéto faktory rozhodovania, bez toho, že by ste ich museli pomenovať (napr. prídu na to, že muži po 50ke, žijúci na vidieku, veľmi často majú deti s inou. A to vám akosi nepasuje do schémy :).
Pre človeka, ktorý nepracoval detailne s neurónovými sieťami, tento rozdiel medzi rozhodovacím stromom a neurónovou sieťou môže pripadať ako drobný. Skutočná hĺbka tohto rozdielu však spočíva v tom, že keďže neurónové siete nepotrebujú vedieť faktory dôležité pre rozhodnutie. Dajú sa teda použiť aj na otázky, v ktorých my sami ľudia nevieme úplne presne, ako vybrať najvhodnejšie riešenie. Inak povedané, neurónové siete by vedeli vybrať relatívne dobrého partnera na rande aj pre ľudí, ktorí nevedia, na základe čoho sa rozhodnúť. Rozhodovací strom bez faktorov, na základe ktorých sa rozhodovať – to by dopadlo rovnako katastrofálne ako v bežnom živote dopadajú ľudia, čo nemajú jasno v kritériách, koho pozvať na rande.
Pre úplnú korektnosť témy treba povedať, že teoreticky aj machine learning modely môžeme “nakŕmiť” len hrubými faktmi rovnako ako neurónové siete. Ale ich výsledky však budú zväčša citeľne horšie, ako dosahujú (dobre natrénované) neurónové siete s rovnakými vstupmi. (Teda napríklad rozhodovací strom odhalí, že čím je muž starší vekom, tým je väčšia šanca, že má deti s inou, ale už nemusí postrehnúť, že táto tendencia sa inak prejavuje pri odlišnej farbe pleti (rôzne národy majú odlišné rodinné pomery)). Rovnako treba povedať, že aj sloboda neuróniek samostatne si vytvárať faktory pre rozhodovanie prestane byť výhodou, ak nie je umožnené sieti vytvoriť dostatočný počet vlastných rozhodovacích vrstiev (o tom však neskôr). Ak necháme bokom tieto extrémy, za priaznivých okolností je postup neurónových sietí inteligenčne nadradený bežným machine learning postupom. Mal by preto dosahovať aj vyššiu presnosť rozhodovania. A to dokonca v oblastiach, kde my ľudia nevieme, aké je optimálne riešenie. To je zrejme jeden z dôvodov prečo začínajúci Data Scientisti túžia pracovať na neurónových sieťach a naopak na “bežný machine learning” sa pozerajú trochu s dešpektom.
Ako to vlastne funguje
Tých menej zasvätených možno prekvapí, že podobne ako mobilný telefón alebo CDčko, neurónové siete predbehli svoju dobu a prišli dávno pred tým, než sme ich začali masovo používať. Prvé primitívne neurónové siete boli zostrojené už takmer pred 70 rokmi. Teda ešte v čase, keď čísla do počítačov sa zadávali cez dierne štítky a o disketách, či USB kľúčoch sa ešte ani nechyrovalo. Zlomom vo vývoji bol vynález postupu Spätnej distribúcie chyby (back propagation), s ktorým prišiel Geoffrey Hinton z Toronta v roku 1986. Tento princíp si zachviľu rozoberieme podrobne, poďme však poporiadku:
 Dôvodom, prečo sa neurónové siete tak volajú, je fakt, že v teoretickej podstate vychádzajú z modelu ľudskej neurónovej bunky. Aj keď v hlave máme rôzne typy neurónov, vo všeobecnosti možno o nich povedať, že každý neurón má jedno, či viac spojení, ktoré prinášajú vstupné vzruchy (v našej hlave sú to chemicko-elektrické signály) a jeden či viac výstupných spojení s ďalšími neurónmi (do ktorých sa prenáša výsledok “rozhodnutia” daného neurónu). Niekde v hlave teda máme aj neurón, ktorý zoberie do úvahy, či daný potenciálny partner na rande má “deti s inou” a zvýši alebo zníži tým šance daného jedinca byť pozvaným na rande. Počítačové neurónové siete fungujú podobne. Majú niekoľko vstupov, cez ktoré im pošleme informácie a jeden či viac výstupov, kam pošlú svoje rozhodnutie. Dôležité pritom je, že jeden neurón sa dlhodobo špecializuje len na jedno rozhodovanie. Teda ten istý neurón, ktorý zapracuje informáciu o iných harantoch potenciálneho partnera, nebude za hodinu rozhodovať o tom, či vonku sneží alebo prší.
Dôvodom, prečo sa neurónové siete tak volajú, je fakt, že v teoretickej podstate vychádzajú z modelu ľudskej neurónovej bunky. Aj keď v hlave máme rôzne typy neurónov, vo všeobecnosti možno o nich povedať, že každý neurón má jedno, či viac spojení, ktoré prinášajú vstupné vzruchy (v našej hlave sú to chemicko-elektrické signály) a jeden či viac výstupných spojení s ďalšími neurónmi (do ktorých sa prenáša výsledok “rozhodnutia” daného neurónu). Niekde v hlave teda máme aj neurón, ktorý zoberie do úvahy, či daný potenciálny partner na rande má “deti s inou” a zvýši alebo zníži tým šance daného jedinca byť pozvaným na rande. Počítačové neurónové siete fungujú podobne. Majú niekoľko vstupov, cez ktoré im pošleme informácie a jeden či viac výstupov, kam pošlú svoje rozhodnutie. Dôležité pritom je, že jeden neurón sa dlhodobo špecializuje len na jedno rozhodovanie. Teda ten istý neurón, ktorý zapracuje informáciu o iných harantoch potenciálneho partnera, nebude za hodinu rozhodovať o tom, či vonku sneží alebo prší.
Spôsobom, ako sa každý jeden neurón rozhodne, sa nazýva aktivačná funkcia. V našej hlave (a pôvodnom primitívnom modeli neurónovej siete) sa predpokladá, že vstupy sú len binárne (má deti s inou /nemá deti s inou). V takom prípade aktivačná funkcia vyžaduje určitý minimálne počet vstupných podmienok aby bolo splnených, aby neurón povedal finálne áno alebo nie. Ak napríklad pre stretnutie na rande zvažuje nejaká konkrétna dáma, či je muž pekný, vtipný a bohatý, môže si povedať, že musí spĺňať aspoň 2 z 3 alebo aspoň jednu z daných 3 podmienok. V súčasnej dobe sa umelá inteligencia posunula tak ďaleko, že dokáže teoreticky pracovať so vstupmi aj číselnej či textovej povahy. Aktivačná funkcia, ktorá dáva na základe vstupov finálnu odpoveď, tak môže byť vo svojej podstate aj veľmi komplikovaná. Z praktických dôvodov sa preferujú také funkcie, ktorá sa dokážu rozhodovať “rázne a s istotou”. Cieľom je, aby čo najmenej rozhodnutí končilo niekde v strede pri “ani áno, ani nie” a aktivačná funkcia bola nútená povedať aspoň “skôr áno” alebo “skôr nie”. Pre matematicky zdatnejších je možné dodať, že takéto vlastnosti majú napríklad funkcie sin(x), hyperbolický tangens, AcrTan, Inverzná odmocnina, ktoré preto často slúžia ako aktivačné funkcie v neurónových sieťach.
Hoci samotné rozhodnutia jednotlivých neurónov sú pomerne primitívne (deti s inou >>> skôr nepozvať na rande), poskladaním veľkého počtu neurónov do vzájomnej siete je možné kombinovať čiastkové rozhodnutia a tým dosiahnuť aj veľmi komplikované . V praxi teda neurónová sieť spravidla má niekoľko vrstiev na seba nadväzujúcich neurónov. Prvá vrstva napríklad môže zobrať ako vstup môj vek a vek potenciálneho partnera a ako výsledok vrátiť odpoveď, či sme si navzájom vekovo primeraný alebo nie. Ďalšia vrstva môže zobrať už hotovú vekovú primeranosť a rozhodnúť, či tento fakt zvyšuje alebo zhoršuje šance jedinca na rande (niektoré dámy majú napríklad slabosť na výrazne starších mužov, iné chcú na rande rovesníka). Aby si mohli medzi sebou jednotlivé vrstvy neurónov odovzdávať čiastkové výsledky, je ešte potrebné nastaviť dôležitosť jednotlivých informácií. Pre niektorých môže vekový rozdiel predstavovať väčšiu prekážku, iní môžu byť tolerantnejší k tomuto aspektu. Dôležitosť odovzdávaného medzi výsledku pre ďalšiu vrstvu sa nastavuje pomocou koeficientu významnosti informácie (alebo aj váhy informácie). Každý výstup neurónu v jednej vrstve má priradenú váhu s akou sa zohľadňuje v ďalšej vrstve. To už sme sa prepracovali k najdôležitejšiemu princípu neurónových sietí.
 Pred vynájdením spätnej distribúcie chyby (back propagation v angličtine) mali všetky siete vopred nastavené, pevné váhy medzi jednotlivými neurónmi. Sieť bola statická v čase. To spôsobovalo jav, ktorý by sme my ľudia nazvali asi tvrdohlavosť. Ak sa totiž o nejakom predloženom prípade rozhodla nesprávne, tým, že váhy boli konštantné, ak ste jej preložili ten istý prípad na opätovné posúdenie, opäť sa rozhodla rovnako nesprávne. To spôsobovalo, že tieto prapôvodné neurónové siete boli schopné sa rozhodovať len o veľmi primitívnych veciach, ktoré sa navyše nemenia v čase. Hintonova spätná distribúcie chyby umožnila presne to, čo mu mi ľudia hovoríme “poučiť sa na vlastných chybách”. Podstatou spätnej distribúcie chyby je totiž, že ak sa sieť pri učení pomýli, neurónová sieť prechádza spätne cez jednotlivé vrstvy a zistí, ktorá čiastková informácia spôsobila najviac odchýlenie sa od správneho rozhodnutia. Avšak nielen “vypátra vinníka”, ale na rozdiel od slovenskej justície, ho aj patrične potrestá. Upraví informačné váhy tak, aby tento čiastkový neurón mal väčší (alebo menší) vplyv na celkové rozhodnutie (niekedy môže totiž nastať chyba aj nedostatočným vypočutím niektorého neurónu, teda pre korekciu je potrebné zvýšiť jeho vplyv). Preto ak, napríklad, neurónovej sieti posunieme na posúdenie krásneho, bohatého a vtipného gay kandidáta na rande, ktorého sieť vehementne odporučí, ale my preferujeme heterosexuálne rande, tak vstupnému neurónu, ktorý nesie informáciu o sexuálnej orientácii, sa na základe spätnej distribúcie chyby upraví koeficient, tak aby zohrával významnú rolu v rozhodovaní.
Pred vynájdením spätnej distribúcie chyby (back propagation v angličtine) mali všetky siete vopred nastavené, pevné váhy medzi jednotlivými neurónmi. Sieť bola statická v čase. To spôsobovalo jav, ktorý by sme my ľudia nazvali asi tvrdohlavosť. Ak sa totiž o nejakom predloženom prípade rozhodla nesprávne, tým, že váhy boli konštantné, ak ste jej preložili ten istý prípad na opätovné posúdenie, opäť sa rozhodla rovnako nesprávne. To spôsobovalo, že tieto prapôvodné neurónové siete boli schopné sa rozhodovať len o veľmi primitívnych veciach, ktoré sa navyše nemenia v čase. Hintonova spätná distribúcie chyby umožnila presne to, čo mu mi ľudia hovoríme “poučiť sa na vlastných chybách”. Podstatou spätnej distribúcie chyby je totiž, že ak sa sieť pri učení pomýli, neurónová sieť prechádza spätne cez jednotlivé vrstvy a zistí, ktorá čiastková informácia spôsobila najviac odchýlenie sa od správneho rozhodnutia. Avšak nielen “vypátra vinníka”, ale na rozdiel od slovenskej justície, ho aj patrične potrestá. Upraví informačné váhy tak, aby tento čiastkový neurón mal väčší (alebo menší) vplyv na celkové rozhodnutie (niekedy môže totiž nastať chyba aj nedostatočným vypočutím niektorého neurónu, teda pre korekciu je potrebné zvýšiť jeho vplyv). Preto ak, napríklad, neurónovej sieti posunieme na posúdenie krásneho, bohatého a vtipného gay kandidáta na rande, ktorého sieť vehementne odporučí, ale my preferujeme heterosexuálne rande, tak vstupnému neurónu, ktorý nesie informáciu o sexuálnej orientácii, sa na základe spätnej distribúcie chyby upraví koeficient, tak aby zohrával významnú rolu v rozhodovaní.
Proces spätnej distribúcie chyby však funguje iba vtedy, ak sieti preložíme veľmi veľa prípadov na posúdenie. Keďže sieť sa učí len na svojich chybách, musí ich urobiť veľmi veľa, aby sa niečo naučila. Navyše jej musíme predložiť čo najviac “exotov”. Ak by sme jej posielali na posúdenie stále len toho istého kandidáta, tak po niekoľkých opakovaniach by sa už váhy nemali ako zmeniť. Jediný typ rande partnera, by nastavil váhy optimálne pre tento typ človeka. Opätovné predkladanie toho istého typu, by už váhy nedokázalo meniť, sieť by sa totiž už nemala ako mýliť. (tomuto javu sa hovorí aj pretrénovanie a pri stavbe skutočne kvalitných neurónových sietí je nutné proti nemu aktívne bojovať). Preto, ešte pred tým než je možné neurónovú sieť použiť na skutočné rozhodovanie (na ostro), je potrebné jej predložiť veľký počet (podľa možnosti čo najrozmanitejších) prípadov na vyladenie váh, aby sa sieť čo najpresnejšie naladila. Pre vytvorenie kvalitnej neurónovej siete je potrebné dodať rozmanité vstupy a čo najviac prípadov, kde vieme ako rozhodnutie má dopadnúť. Ak by som mal teda vytvoriť kvalitný model na výber partnera na rande, museli by ste mi predložiť čo najviac vecí, ktoré (možno aj podvedome) vstupujú do rozhodovania a dať mi rozsiahly listing ľudí, s ktorými by ste chceli alebo naopak vôbec nechceli ísť na rande.
Čo z toho plynie
Nutnosť vysokého počtu trénovacích (tzv. anotovaných) prípadov je jedným z dôvodov, prečo v týchto oblastiach umelá inteligencia ešte ani z ďaleka nedosahuje výsledky blížiace sa ľuďom. Je totiž jednoduché (a stroje už dnes vedia dobre) rozoznať naše emócie z fotky (je pomerne ľahké dodať veľký počet ľudských fotiek s popisom akú emóciu človek na fotke vyjadruje). Je však omnoho komplikovanejšie pre všetky jazyky sveta dodať také množstvo textov, aby stroj presne odhadol našu emóciu v ľubovoľnom jazyku. Hlavne keď pre vety typu “Ty brďo!” sa skutočná emócia dá rozoznať iba na základe tónu hlasu alebo kontextu iných viet povedaných tesne pred alebo po tomto výroku. Vyššie spomenuté má za následok, že stroje budú vedieť iba to, na čo im ľudia predložia dostatočne veľa anotovaných podkladov. To otvára niekoľko filozofických možností, ako s neurónovými sieťami do budúcna naložiť. Zároveň to vysvetľuje, prečo hry ako šach boli prvé, v ktorých stroje porazili človeka (každá šachová partia má jasne určeného víťaza a pomocou spätnej distribúcie chyby je možné každému ťahu priradiť vplyv na celkové víťazstvo v partii).
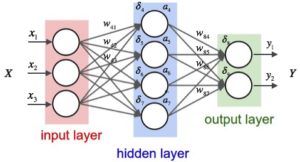 Pre odborné dokreslenie problematiky, v neurónových sieťach sa rozlišujú zvyčajne tri druhy vrstiev: vstupná vrstva (to sú neuróny, ktorú nesú pôvodné vstupné informácie, napr. vek, sexuálne orientácia, telesná výška potenciálneho rande partnera a pod.), skrytá vrstva (kde sú neuróny, ktoré používajú dostupné vstupy pre vytvorenie čiastkových rozhodnutí. Kvalitné neurónové siete môžu maj niekoľko desiatok skrytých vrstiev, lebo musia zohľadniť veľa čiastkových vplyvov na celkové rozhodnutie. ), výstupná vrstva (ktorá obsahuje už neuróny dávajúce finálne rozhodnutie. Väčšina sietí je budovaná pre jedno výstupné rozhodnutie, ale neurónová sieť môže dodávať aj viac rozhodnutí naraz. Napr. či pozvať na rande a v ktorý deň v týždni pozvať na rande, do akého miesta rande situovať alebo akou formou komunikácie najlepšie pozvať daného človeka na rande)
Pre odborné dokreslenie problematiky, v neurónových sieťach sa rozlišujú zvyčajne tri druhy vrstiev: vstupná vrstva (to sú neuróny, ktorú nesú pôvodné vstupné informácie, napr. vek, sexuálne orientácia, telesná výška potenciálneho rande partnera a pod.), skrytá vrstva (kde sú neuróny, ktoré používajú dostupné vstupy pre vytvorenie čiastkových rozhodnutí. Kvalitné neurónové siete môžu maj niekoľko desiatok skrytých vrstiev, lebo musia zohľadniť veľa čiastkových vplyvov na celkové rozhodnutie. ), výstupná vrstva (ktorá obsahuje už neuróny dávajúce finálne rozhodnutie. Väčšina sietí je budovaná pre jedno výstupné rozhodnutie, ale neurónová sieť môže dodávať aj viac rozhodnutí naraz. Napr. či pozvať na rande a v ktorý deň v týždni pozvať na rande, do akého miesta rande situovať alebo akou formou komunikácie najlepšie pozvať daného človeka na rande)
Rôzne rozloženie (topológia) neurónov do vrstiev umožňuje špecializovať sa sietiam na konkrétne druhy úloh/rozhodnutí. Ak chcete naučiť robota variť, musí si napríklad pamätať svoje vlastné, už realizované kroky a sledovať ich dopad (napr. omáčka mi pomaly hustne). Naopak ak chcete rozoznať, či je na obrázku opica, tak, čo bolo na predchádzajúcom obrázku, nie je pre rozhodnutie o tomto konkrétnom obrázku zrejme dôležité. V ďalších dieloch si preto povieme:
V čom sa 8 ročné dieťa smeje neurónovým sietiam?
Akú máme vlastne alternatívu voči umelej inteligencii?
Koľko rôznych druhov neurónových sietí vlastne poznáme? [coming soon]
Ak ste sa k našej sérii blogov o neurónových sieťach dostali neskôr a chceli by ste ju čítať od počiatku, začnite tu.
Publikované dňa 10. 1. 2018.