You may be surprised by this question. Because most of us have at most a choice between whether to take the test or not. (Some of them still have bad luck in this as well.) And the idea that at the testing point they will place several different boxes in front of you and offer you a choice resembles more of a street gamble scene with three cups and a ball under one of them. But close your eyes for a moment and try to imagine that you could really choose: By what criteria would you choose the test? Fastest? What’s the least painful?
I think most of us would choose the most accurate test possible. But that’s exactly the trap of the debate. As you will learn soon, each test has by its very nature 4 metrics of “quality”. So if you say you want a test with 99% “measurement quality”, without a deeper insight into matter, you can end up with 4 completely different tests that each are 99% “accurate”. (In addition, each time you repeatedly test the same person, you will get a completely different positive / negative share of among the tests). Therefore, this blog explains which of the 4 metrics will be most important to you and how high the metric value should be. The blog also explains why I solve this quality dilemma on a daily basis, though I don’t work with COVID tests at all. But let’s save that matter until the very end of this text.
 Before I fulfill the above-mentioned promise of initiating you into testing accuracy, please allow me two short, personal notes. I have had this blog in progress for several weeks by now, but this week’s statement by the Slovak government that it wants to test the entire Slovak population (by antigen tests) has pushed me to finish it quickly. I believe that the information from blog(s like this) will be important for the discourse of the coming days (and one’s decision on whether to take part or not in this population test voluntarily). The second personal point is that today it is exactly 10 years since I started writing blogs! Unfortunately, there was no cake with candles. But as you can see, I celebrated blogging anniversary with, ehm, blog work. I can’t promise to keep myself blogging for another 10 years. But I’ll do my very best to make this (295th) blog, as interesting and inspiring a read, as more than half a million unique views of my previous blogs were. Now back to the tests.
Before I fulfill the above-mentioned promise of initiating you into testing accuracy, please allow me two short, personal notes. I have had this blog in progress for several weeks by now, but this week’s statement by the Slovak government that it wants to test the entire Slovak population (by antigen tests) has pushed me to finish it quickly. I believe that the information from blog(s like this) will be important for the discourse of the coming days (and one’s decision on whether to take part or not in this population test voluntarily). The second personal point is that today it is exactly 10 years since I started writing blogs! Unfortunately, there was no cake with candles. But as you can see, I celebrated blogging anniversary with, ehm, blog work. I can’t promise to keep myself blogging for another 10 years. But I’ll do my very best to make this (295th) blog, as interesting and inspiring a read, as more than half a million unique views of my previous blogs were. Now back to the tests.
4 success metrics
When we deliberate how well things works, we usually think in terms of % reliability. If we find out that something works at 90% (or more) percent, we usually stress down. It doesn’t occur to us that we should seek any other metrics of success. We simply expect it to turn out well in roughly 9/10 cases.
Therefore, the revelation that there are some other measures of success of a product or service, and even that there are 4 of those metrics, might seem like fate’s irony or pointless meticulousness. This confusion in our head arises from fact we do not look at things strictly in factual basis. Often, we forget that the very real state of something we aim to study may not be known; and we try to guess the real state out of someone’s observation. Such situations are common in our lives: think you and classmates playing in a school yard. Some of you broke a window and a class teacher comes to solve this window issue. 4 possible scenarios could occur: You didn’t break the window, but you still got rebuked by the teacher; you broke the window and were rebuked justifiably, but equally the possibility is that you broke the window and unfairly escape reprimand, or you did not break the window and was not rebuked. So if someone (in our example, a class teacher) tries to solve the case of a broken window, suddenly she has several goals to deliver: to reveal the real culprit, not to blame other children, but to make it clear that this is unacceptable to repeat again, …
No less of confusion it is even in science, when measuring or testing things. This is also evidenced by the fact that the scientists themselves named the method of solving such situations as the Confusion Matrix. Its simplest form looks like this:

In principle, it is a 2-by-2 chart (the wiseacres would say that it can be more than 2-by-2, but let’s not meddle it here). One dimension is the real state of affairs (he broke the window, he really has COVID, he really murdered, …) and the other dimension is what the test / observation / estimate said about the state (he was reprimanded, the result of the COVID test, the court found person guilty …). Combinations of these two dimensions create 4 possible states:
True Positive (TP) = a person to whom the test correctly estimated that a given phenomenon actually occurred to him (eg justly convicted)
False Positive (FP) = a person who is actually negative but the test falsely accused him of being positive (eg falsely accused innocent)
True Negative (TN) = A person who has been correctly estimated by a test to be truly negative in a given phenomenon (eg, justly acquitted)
False Negative (FN) = Wrongly marked as negative = a person who is actually positive, but the test did not reveal it and claims to be negative. (eg wrongfully released real offender)
By the nature of the matter, of course, we don’t mind TN and TP, because they marked things correctly. The fields of FN and FP are confusing the matter. However, for the correct assessment of the “quality of the test”, mutual relations among the 4 possible outcomes are also important. As result the following 4 metrics arise to enable complete assessment of the situation:
Overall accuracy = the ratio of those for whom the test guessed their true state correctly, thus = TP + TN / (FP+FN+TP+TN)
Sensitivity = (Recall ) = Detection rate for those whose test really should have revealed the phenomenon = TP / (TP + FN). With 100% sensitivity, the test revealed everyone who was tested and was really positive. At 50% sensitivity, the test “forgot” to mark every second truly positive.
Specificity = Rate of correct marking of negative in those being with negative test result = TN / (TN + FP). With 50% specificity of the test, half of the negatives are erroneously marked as positive.
Predictive power of positive test = (Precision ) = Probability that the person is positive, if the test said so = TP / (TP + FP).
(The little secret of more informed is that there are actually more than 4 metrics, but the other (not mentioned here) metrics can be derived from most common (and here mentioned) 4 ones)
How to chose the proper test?
 So what? Do you already have your favorite of the 4 metrics listed? If you think it is enough to have a high overall accuracy, you are dangerously wrong. Try the following example: You have 2 lie detectors, both of which are 90% successful in overall. However, detector A has the remaining 10% on top of the successful readings in the FP box and detector B has them in the FN box. In terms of overall success, you should not care about what you want to be examined on. However, the essential difference between A and B is: Whenever detector A is unsure, it will identify you as guilty, while B whenever it gets unsure will label you as innocent. So what? Still don’t care which one to take?
So what? Do you already have your favorite of the 4 metrics listed? If you think it is enough to have a high overall accuracy, you are dangerously wrong. Try the following example: You have 2 lie detectors, both of which are 90% successful in overall. However, detector A has the remaining 10% on top of the successful readings in the FP box and detector B has them in the FN box. In terms of overall success, you should not care about what you want to be examined on. However, the essential difference between A and B is: Whenever detector A is unsure, it will identify you as guilty, while B whenever it gets unsure will label you as innocent. So what? Still don’t care which one to take?
The whole selection matter gets complicated by the fact that different social processes/decisions require an emphasis on different metrics of success. With the broken window mentioned, the class teacher will probably primarily aims that this act does not go unpunished. (for moral reasons) Therefore, if the children deny the responsibility each and they try to cover each other, then teacher will (threaten to) punish all involved. In doing so, she is guided by maximizing the Sensitivity even at the cost of a low Predictive power of the positive. In other words, we prefer a few unwarranted reprimands over leaving anyone unpunished for a broken window.
On the contrary, Sensitivity is often the most important consideration in medicine (undetected internal bleeding is worse than incorrect suspicion of it), but for tests that lead to surgery, chemotherapy or other irreversible procedures, Precision is also very important. Having an unnecessarily amputated limb or a torn tooth is also not a top notch health care.
On the contrary, the presumption of innocence in our justice system is a pure focus on Specificity even at the cost of low Sensitivity. In other words, 10 acquitted criminals rather than 1 unjustly convicted. How painful to accept this is has surely experienced any democratic community.
To elicit correct decision, it is necessary to say what happens to testing if, some of test quality metric(s) are weak. If a decision-making process has a low rate of Positive Predictive Measure, it means that many people have been falsely identified as positive and this will significantly undermine the credibility of such a process (people will not complain if they are mistakenly declared innocent, but will revolt if many marked guilty are innocent, matter-of-factly). On the other hand, low sensitivity means that if something is to happen as a consequence of a positive test (eg treatment), many people will not get that, even if they deserve/need it. Thus, the costs and consequences of undetected cases kick-in. This might mean also as tragic things as unnecessary deaths in healthcare, or more preventable infections. Low Specificity, in turn, leads to unnecessary exposure to the consequences of a positive test, whether in the form of unfair imprisonment, unnecessary treatment, and stress for people who are labeled as (sometimes even terminally) ill, though they are super healthy. What is more, it might also lead to unnecessary financial waste (for example, when granting discounts or deciding to whom to send a offer letter with costly sample item). Finally, the low overall accuracy is bad in itself and says that you probably have the wrong test, first place.
What to take out of it for COVID testing
The development of the COVID pandemic has so far brought 3 basic types of COVID tests to the table. They differ not only in their testing approach, but also, unfortunately, in which success metrics they emphasize. But it is not the negligence or malice of their creators. Simply given tests are intended for different situations, where this or that metric of success plays a unique(ly important) role. For your basic orientation, I compiled a table with 3 basic types and their success metrics:
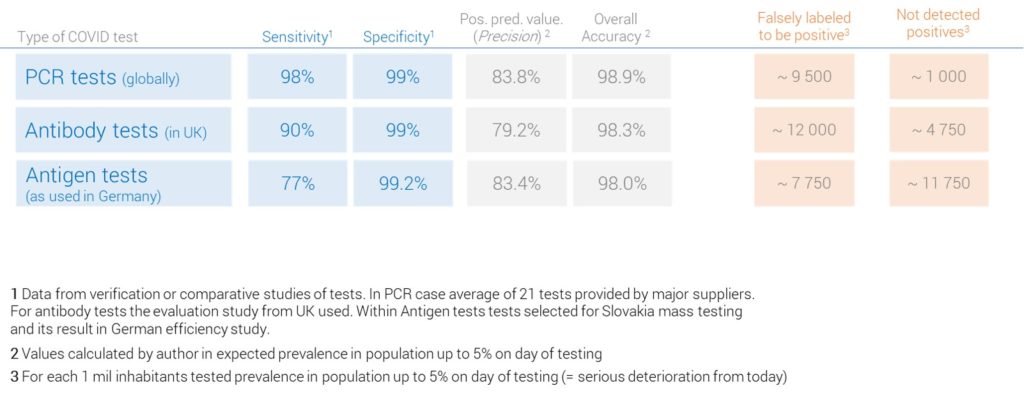
A cursory glance at the table shows that the overall best accuracy is achieved by PCR test and their Antigenic cousins (selected for mass SR testing) have the worst scores. To stay on the correct terms, it must be said that antigenic tests are the only tests with which such a extensive population testing can be physically performed. It would take more than a month to evaluate PCR tests for the whole country (even with the effort of all forces and foreign help) and cost would mount to at least 10 times more than Antigen-variant. Antibody tests would be cheaper and more feasible than PCR, but their primary goal is to confirm the course of COVID disease in suspects who have been infected for at least 2-3 weeks (which is not exactly a tool to isolate and prevent the spread of the virus). Given the possibilities of the government, it cannot be concluded that they chose antigenic tests (in reality, there was no real, feasible option). However, mass testing in Slovakia with this tool would mislead about 80,000 households as to whether or not they have COVID. Almost 50,000 of them would have the virus and be reassured that they don’t and they can do everything the old way, after all, they had a negative test. If you live in an 8-storey block of flats, on average at least one family in your gate would be quarantined undeservedly. Whether you should join this government mass testing action (if you have a choice, first place), I will leave to your discretion. So far, the risks of participating in such a test have been little pointed out (eg waiting in line with potentially infected people, traveling to the testing site, …), but their real impact will depend on how the whole event is logistically organized. Up to now we have only heard that “it will be like elections” on the logistics account. Well, if all this is to make impact, it remains to be hoped at least for elections other European Parliament vote (where Slovakia has about 20% turnout). When deciding whether or not to go, I especially wish you calm head and a bit of common sense. I hope this blog also gave you some more food for thought. If you still have 2 minutes more, the next paragraph depicts how interestingly I come into contact with above stated 4 metrics of success at my work.
What does it all have to do with my job
For regular readers of themightydata.com, I bring a few more lines about what are the most important conclusions from Confusion Matrix for our work with data. Majority of models predicting behavior have the nature of (binary) classifiers = indicating whether something is this or its opposite. However, that means that classifier essentially resemble (COVID) tests. Hence, the above 4 metrics of success also come into play when deciding which prediction model to deploy in the final production. Most beginners make the mistake of looking only at Accuracy metric. This is probably due to the fact that it is the default metric in many model evaluation statistical packages. Those slightly more advanced recognize that in reality picking the right production model is more a fight of Precision versus Recall. Why so? Models are usually quite confident in apparently positive and apparently negative individuals. Their issue remains where to lean in the middle unclear opinion waters (do you still remember lie detectors A and B?). However, what often confuses even the advanced analysts (don’t worry, after all it’s a Confusion Matrix :), that in some models Recall is more important than Precision. Have some doubts?
Well, imagine a model that tries to predict the churn of clients to offer them some small relief and persuade them to stay with our customers. For such a model, it is much more dangerous if it does not identify some actually departing clients rather than if it undeservedly labels some satisfied clients as churners. Therefore, optimizing the model for Recall is much more important here than taking care for Precision. On the other side of the coin, if we do an X-sell campaign where we send a free product sample, good Precision may be more important than Recall. If the campaign is successful (a large percentage of contacted purchases), we will easily get the budget to extend into next round that campaign (which will also address those (wrongly) marked as less likely to buy). But if we (due to low Precision) in first wave of campaign rather send an unnecessarily large volume of product samples (in attempt to capture everyone), the campaign will be immediately in red numbers, considered a loser and spared of chance to correct for that.
That is reason why I have to regularly decide in my work which of the 4 success metrics we will optimize for. So, similarly as with COVID tests, we strive to choose the greatest good, or at least the least evil. This can only be done, of course, only if you inspect all the Confusion matrix metrics for every prediction model; which I would strongly like to encourage you to. On top of it, comparing FP, TP, FN and TN groups can also provide hints on how to improve the model itself. But that’s something for separate blog post next time. Thanks for reading that far and make smart choices of (not only) WHICH COVID TEST would you take! Stay Healthy!
Publikované dňa 22. 10. 2020.