Many of us have probably already played with new-kid-on the-block of the Artificial intelligence space, ChatGPT from OpenAI. Providing prompt of any question and getting no-gibberish, solid answer, very often factually even precise is fascinating experience. But after few awe moments of getting answer to your “question of the questions” you maybe wondered how does the Chat GPT actually really work?
If you are top-notch Data scientist you could probably go into documentation (and related white-papers) and can simulate (or even write own) transformer to see what is going under hood. However, besides those few privileged, usual person is probably deprived of this, ehm, joy. 😊 Therefore, let me walk you through the mechanics of ChatGPT in robust, but still human-speak explanation in next few paragraphs (and schemas). Disclaimer = I compiled this overview based on publicly available documentation for the 3.0 version of the GPT. The newer versions (like 4.0 ) work with same principles but have different size of neuron nets, look-up dictionaries and context vectors, so if you are super-interested into how the most recent version works, please extend your research beyond this article)
6 main steps
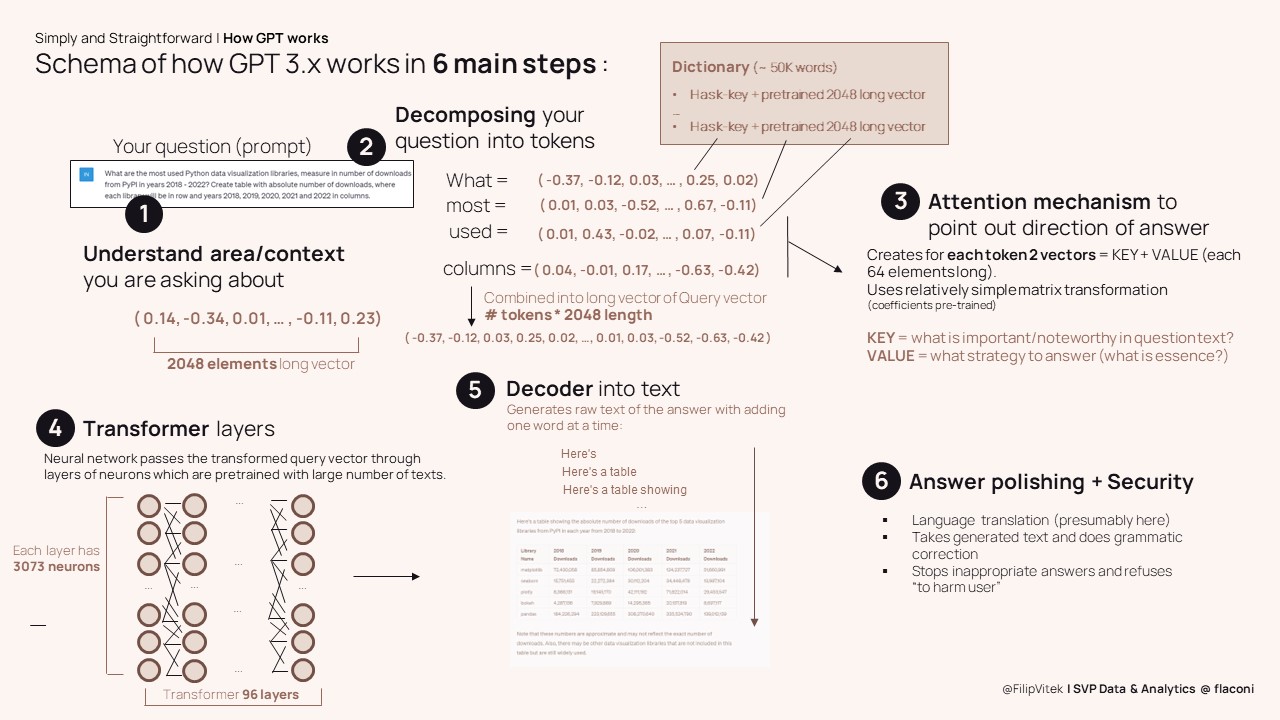
Even though our interaction with ChatGPT looks seamless, for every query to it, there are 6 steps going on (in real time). Media label the ChatGPT in single phrase as “artificial intelligence”, but it is worth mentioning that of these 6 steps, only 2 and half are actually real artificial intelligence components. Significant part of the ChatGPT run is actually relatively simple math of manipulating vectors and matrices. And that makes the details of the ChatGPT even more fascinating, even for the “lame” audience.
It’s start with compressing world into 2048 numbers
The first step of the ChatGPT work is that it reads through the whole query that you provided and scans for what are you actually asking. It analyzes the words used and their mutual relations ships and encodes the context (not yet the query itself, just the topic) of the question. You might be amazed by fact that ChatGPT converts whole world and possible questions you ask into combination of 2048 topics (represented by decimal numbers). In a very simplifying statement you can say that ChatGPT compresses the Internet world into 2048-dimensional cube.
Context first, then come tokens
As outlined in previous paragraph, in process of answering our prompt the ChatGPT first takes some (milliseconds) time to under the context of the query before actually parsing through the query itself. So after it decides, who area(s) of “reality” you are interested in, than it meticulously inspects your entire question. And it literally does so piece by piece, as it decomposes the given question into tokens. Token is in English usually a stemmed word (base) with ignoring the stop-words or other meaning non-bearing parts of the text. In other languages token can be obtained differently, but as rule of the thumb: number of tokens <= number of words in the question.
For every token the GPT engine makes a look-up into predefined dictionary of roughly 50K words. Using hashed tables (to make the search super fast), it retrieves a vector (again 2048 elements long one) for each token. This way each word of the query is linked to topic dimensions. As the system does not know in advance how many words will your request have, there needs to mechanism to accommodate for any (allowed) length of the query. To be flexible with this, chatGPT forms a extremely long vector (2048 * number of tokens), in which the sub-vectors coming from dictionary lookup for each token is arrange one after another into sequence. Therefore 100 words long query might have even up to 204 800 vector elements. even larger 500 words request might have more than 1 mil of the letters. This vector is than processed, but first we need to do one more important change.
Where to look (or How to swim in this ocean of data)
As we learned 500 words long request to ChatGPT might arrive at more than 1 mil numbers encoding this request. That is a real ocean of the data. If you as human received such a long prompt for answer, I guess you would struggle even with where to focus the attention first place. But no worries here, so would the GPT if it was not for the Attention mechanism. This AI technique researched only in last 10 years (papers from 2014 and 2017) is the real break0through behind GPT and is also the reason why language models were able to achieve the major step-up in “intelligence” of communication.
The way that Attention mechanism works, it calculates (still through linear algebra matrices) pair of two (relatively short vectors) for each of the token. These vectors are labeled as KEY and VALUE. They are representation of what is really important (and why) in the text. This way the engine does not force neural network to put equal weight ( = focus) on all million input numbers, but select which subsection of the query vector are crucial for answering the question. When then combined into transformed SUM of the elements, it provides the recipe for how to “cook” the answer to question. what might sound like (yet another) complication, is actually key simplifier and energy saver. While past approached to language moles assumed “memory” holding equally important each word of the query text (or assigning same, gradual loss of attention into previous words). That was prohibitive expensive and hence limited the development of better models. Therefore, jumping over the attention hurdle unlocked the training potential of AI models.
Finally AI part
It might be counter-intuitive for many, but first 3 steps of the GPT have actually nothing to do with Artificial Intelligence. It is only step 4, where the real AI magic can be spotted. Essence of the 4th step is the Transformer core. It is a deep neural network, with 96 layers of the neurons, a bit more than 3000 neurons in each of the layers. The transformer part can be actually named also the Brain of the GPT. Because it is exactly the transformer layers that store the coefficients trained from running large amounts of texts through neural network. Each testing text used for training of the AI, leaves potentially trace in the massive amount of the synopses between the GPT “neurons” in form of the weight assigned to given connections.
As unimaginable the net of hundreds thousands (or millions) neurons are to us humans, so is the actual result of the Transformer part of GPT is probability distribution. No, not a sequence of words or tokens, not a programmed answer generating set of rules, just probability distribution.
Word by word, bit by bit …
Finally in step 5 of the Chat GPT we are ready to generate the textual form of the answer. GPT does that by taking the probability distribution (from step 1) and running the decoder part of the Transformer. This decoder takes distribution and finds the most probable word to start the answer with. Then it takes the probability distribution again and tries to generate second word of the answer, and third, then forth and so on, until the distribution of probabilities calls special End-of-request token. Interestingly enough, the generation does not prescribe how many words will the answer have, neither it defines some kind of satisfaction score (on how much you answered the query already with so-far generated sequence of words). Though ChatGPT does not hallucinate the answer or bets on single horse only. During the process of the creation of the answer there are (secretly) at least 4 different versions (generated using beam search algorithm). Application finally chooses one that it deems most satisfactory for the probability distribution.
Last (nail) polish
As humans, we might consider the job done by step 5 already, so what on Earth is the sixth step needed for? Well anybody thinking so, forgets that human person talking formulates the grammatically correct (or at least most of us) sequence. But AI needs a bit of the help here. The answer generated by Decoder still needs to undergo several checks. This step is also place where filtering or suppressing of the undesirable requests is applied. There are several layers on top of the generated raw text from previous stage. This is also (presumably) place where translation from language to language happens (e.g. you enter you question in English, but you ask GPT to answer in Spanish). The final result of the query answer has been delivered, user can read through. And ask next question 🙂
The flow of the questions in the same conversation thread can actually lead to updating or tweaking the context parameters (Step 1) of given conversation. The answering context thus gets more and more precise. Strikingly, the Open AI’s GPT models actually store each of the conversation, so if you need to refer back to some past replica of conversation, GPT will still hold the original questions and answers of that talk branch. Your answer (and questions) remain thus historized and in full recall any time in future. Fascinating, given the number of users and queries that they file.
Steps Summarized
The above described steps of the GPT answer building have been neatly summarized into following slide, providing additional details and also indicating the transformations made in individual steps to enable the total answer flow. So if you want to internalize the flow or simply repeat the key training architecture/principles, please read through the following summary:

Few side notes to realize …
Though the actual mission of this blog post is to walk the reader through the (details of) process of generating the answer to the query prompt for GPT, there are few notable side facts stemming from the way that GPT is internally organized. So if you want to collect few “fun fact” morsels that make you more entertaining dinner buddy for your next get-away with friends (or for Sunday family lunch), here is few more interesting facts to be aware of (in GPT realm):

And bit of zoom-out view
Besides the fascination with HOW actually ChatGPT works, I often receive also questions about it’s future or speed of the past progress. I summarized the most common questions (I received) into below show-cased 1-pager. So if your curiosity is still on high level, feel free to charge yourself with these FAQs:

 Let me unbox the most interesting piece here first and then support it with a bit of the details. So, dear real human candidates, the ChatGPT did not get hired. BUT it scored 61 points. Therefore, if OpenAI keeps on improving it version by version, it might get over the minimal threshold (soon). Even in tested November 2022 version, it would beat majority of the candidates applying for Senior data science position. Yes, you read right, it would beat them!
Let me unbox the most interesting piece here first and then support it with a bit of the details. So, dear real human candidates, the ChatGPT did not get hired. BUT it scored 61 points. Therefore, if OpenAI keeps on improving it version by version, it might get over the minimal threshold (soon). Even in tested November 2022 version, it would beat majority of the candidates applying for Senior data science position. Yes, you read right, it would beat them!