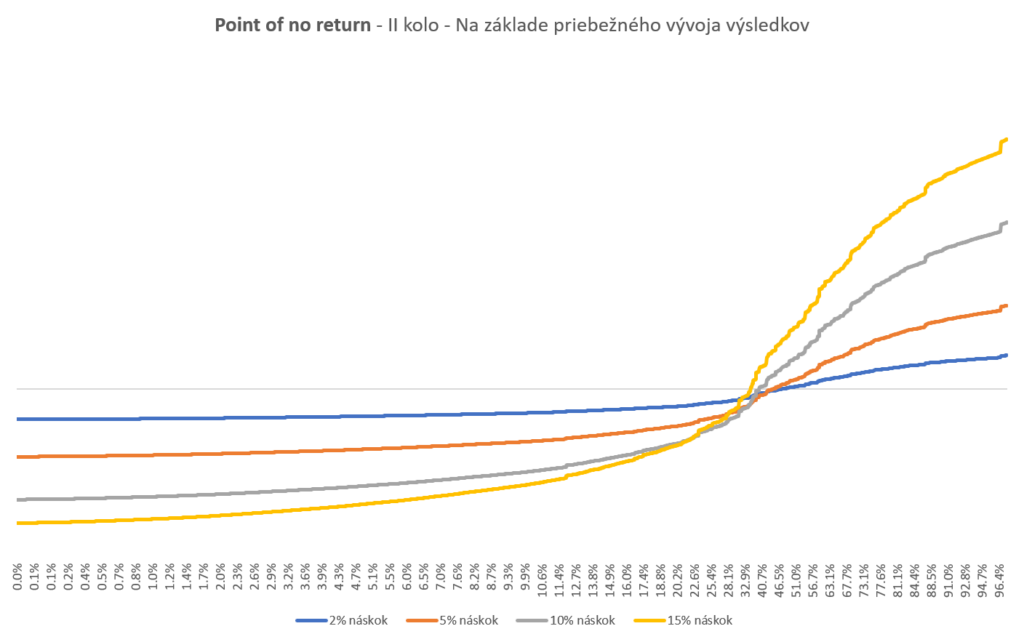
Otázka súkromia v aktuálnej digitálnej dobe zväčša pendluje medzi 2 extrémami. Na jednej strane ľudia bezstarostne odovzdávajú svoje údaje (takže taký mobilný operátor vie o vás viac ako vy sami) alebo priam nakupujú tovar výmenou za svoje Facebook statusy. Výsledkom sú potom takéto nástroje, ktoré slúžia ako jadrové zbrane marketingu a vyvolávajú škandály.
Na strane druhej existujú početné sily aktivistov, ktorí majú pocit, že už sme dátovo nahí a ktorí (najmä v EU) presadili najtvrdšie pravidlá ochrany súkromia na svete. (aj keď GDPR implementácia priniesla zopár humorných momentov). A tak sa ochrana digitálneho súkromia stáva čoraz viac rozdeľujúcou témou.
Šípkové kráľovstvo dátových analytikov
 Oblasť dátovej analytiky by sa síce mohla tváriť „Ja nič, ja muzikant“, ale tento postoj by bol pomerne cynický a ťažko uveriteľný. Väčšina osobných údajov, ktoré sa v biznise svete ukladajú, sú zbierané práve za účelom dátovej analytiky. Preto stáť opodiaľ by pre dátových analytikov bolo ako keby sa Báthorička tvárila, že nevie prečo sa jej napúšťa voda do vane.
Oblasť dátovej analytiky by sa síce mohla tváriť „Ja nič, ja muzikant“, ale tento postoj by bol pomerne cynický a ťažko uveriteľný. Väčšina osobných údajov, ktoré sa v biznise svete ukladajú, sú zbierané práve za účelom dátovej analytiky. Preto stáť opodiaľ by pre dátových analytikov bolo ako keby sa Báthorička tvárila, že nevie prečo sa jej napúšťa voda do vane.
V obhliadnutí späť si preto myslím, že odpoveď dátovej analytiky „si dala celkom na čas“. Analytika sa potácala sa medzi čierno-bielym videním dátového súkromia a až nástup novej generácie dátových analytikov priniesol poznanie, že Machine learning modely je možné tvoriť aj citlivo voči dátam klientov. Toto „pánske huncútstvo“ sa však objavilo len vo veľkých spoločnostiach, ktoré určovali trendy na trhu (a zaoberať mali dosť kapacity zaoberať sa vôbec niečím tak „banálnym“ ako súkromím klientov). Vo väčšine firiem, sa táto téme nedostala na „jedálny lístok“. To je aj dôvod prečo GDPR regulácia bola tak tvrdá, lebo pred jej zavedením vládla vo firemnom sektore ignorancia práv klientov (či prinajmenej ich absolútna neznalosť).
A pritom to ide …
Ako každé systematické úsilie, aj cielené implementovanie ochrany súkromia do procesov strojového učenia dátových modelov si vyžaduje viac ako kozmetické zmeny v postupoch práce. Ak nemáte v teame niekoho, kto k tomu v zahraničí pričuchol, dúfať, že sa vám podarí ich správne nastaviť len tak, spontánne, je naozaj naivné. Som preto rád, že „veľkí“ sa rozhodli pomôcť malým a vznikajú tak vzdelávacie kurzy o tom Ako robiť analytiku citlivo k súkromiu. (môžete sa aj vy prihlásiť zdarma). Tí, čo naozaj chcú robiť dátovú analytiku (spoločensky) zodpovedne, tak môžu zaviesť do svojej práce to najlepšie, čo na svete existuje pre rešpektovanie digitálneho súkromia.
nemáte v teame niekoho, kto k tomu v zahraničí pričuchol, dúfať, že sa vám podarí ich správne nastaviť len tak, spontánne, je naozaj naivné. Som preto rád, že „veľkí“ sa rozhodli pomôcť malým a vznikajú tak vzdelávacie kurzy o tom Ako robiť analytiku citlivo k súkromiu. (môžete sa aj vy prihlásiť zdarma). Tí, čo naozaj chcú robiť dátovú analytiku (spoločensky) zodpovedne, tak môžu zaviesť do svojej práce to najlepšie, čo na svete existuje pre rešpektovanie digitálneho súkromia.
Ak pracujete v analytike už aspoň 3-5 rokov, nebudem prekvapený, ak vás v doterajšom priebeh tohto blogu trochu „tlačí v topánke“ otázka „Čo vlastne možno pre ochranu súkromia urobiť až pri ich samotnom analyzovaní?“ Podobne ako vy, na začiatku svojej kariéry som predpokladal, že dáta sa majú chrániť primárne pri zbieraní, teda ešte ich analyzovaním. Tvorbu prediktívnych modelov som pokladal za „nevyhnutné zlo“ biznisu s primeraným zásahom do súkromia koncového klienta. Čo sa dá teda robiť ešte počas modelovania inak?
Tri oriešky pre … ochranu dát
 Tak ako lieky majú svoje nežiaduce vedľajšie účinky, aj trénovanie prediktívnych modelov (a iné analyzovanie dát klientov) má 3 základné neduhy, ktoré negatívne vplývajú na dátové súkromie:
Tak ako lieky majú svoje nežiaduce vedľajšie účinky, aj trénovanie prediktívnych modelov (a iné analyzovanie dát klientov) má 3 základné neduhy, ktoré negatívne vplývajú na dátové súkromie:
Zdanlivo nenápadným vedľajším efektom dátovej analytiky je fakt, že pre posúdenie vzájomných vplyvov jednotlivých faktorov správania klienta je potrebné ich zhromaždiť na jedno miesto. Aspoň tak si to predstavovala pôvodná metodika dátového modelovania, ktorá zhŕňala všetky možné faktory do Analytických profilov (klientov), ABT tabuliek a iných „zdrojov“ modelovania. Často tak citlivé údaje (ako RČ) boli vo vedľajšom stĺpci od triviálnych údajov ako dátum prvého nákupu. Kumulácia vstupných parametrov, často aj tých, ktoré pre daný model priamo nepotrebujete, je pritom jednou z najhrubších foriem zásahu do súkromia klienta. Analytik, ktorí realizuje analýzu potrebného správania, totiž má k dispozícií údaje aj o mnohých iných návykoch klienta, na ktoré možno klient ani nedal súhlas na skúmanie. GDPR robí spoločné „skladovanie dát“ niektorých typov dát priam nezákonným a preto čoraz intenzívnejšie sa o slovo hlási Federated learning. Tento postup umožňuje držať jednotlivé oblasti správania klienta v oddelených „skladoch“ a pre účely modelovania len „prepožičať“ hodnoty bez odhalenia iných, nesúvisiacich javov alebo skupín klientov.
Jedným z vážnych problémov diskusie o digitálnom súkromí je fakt, že samotné súkromie je pojem prudko subjektívny. Niekomu nevadí ísť na nuda pláž, iná sa skôr cíti na jednodielne plavky. Rovnako je to s digitálnym súkromím: Ťažko ho chrániť, keď vlastne nie je objektívne definované, čo to je. Tomu nedostatku (často vydávanému za lacnú výhovorku na ignorovania digitálneho súkromia) odzvonila oblasť poznania s názvom Differential privacy. Dala si zacieľ objektívne (matematicky) popísať úrovne súkromia (a jeho narušenia). Čo na prvý pohľad môže vyznievať ako akademická diskusia o počte zrniek piesku na zemi, má v skutočnosti podstatné praktické dopady. Akonáhle máte objektívnu metriku súkromia, môžete porovnať dva postupy z hľadiska miery ich invazívnosti do súkromia. Rovnako si môžete stanoviť nejaký firemný cieľ, o koľko by ste chceli zlepšiť ochranu súkromia svojich klientov. Jednotka ochrany súkromia vám nakoniec umožní aj dať do súvisu 1 EUR dodatočných tržieb s mierou dodatočného zásahu do súkromia a tak samoregulovať mieru nevhodných zásahov.
V dobe, keď dáta putujú najmä internetom, cloudovými službami alebo spoločnými úložiskami, ich ochrana pri presune naberá na významnosti. Zakiaľ na kryptované PDF, Excely, či iné prílohy emailov sme si už zvykli, počas dátovej analýzy zostávajú dáta väčšinou v surovej, nechránenej povahe. Vzniká tak odvetvia analytiky, ktoré sa volá Encrypted Computation a ktoré si za cieľ kladie práve zabezpečiť ochranu dát „pred nežiaducim odpozorovaním“ pri príprave dát na modelovanie alebo počas samotného trénovania modelov. Metódy ako Secret sharing, či NoSQL Encrypted Access, vám priblížia ako rozumne zladiť dodatočné nároky kryptovania s efektívnym trénovaním modelov.
Práve okolo týchto troch neduhov sa točí aj vyššie citované školenie, na ktoré sa môžete aj vy zadarmo prihlásiť. Pomôže vám tak možno položiť prvé kamene pre spoločensky zodpovednú dátovú analytiku. Buďte však pripravení na to, že vo svojom okolí budete rovnako početní (a braní vážne) ako aktivisti Greenpeace alebo zástancovia migrácie. Biznisy totiž príliš dlho bačovali s dátami klientov neobmedzene. A väčšina GDPR implementácií sa zamerala skôr na to, ako „zlegalizovať“ už bežiace postupy, než rozmýšľať nad tým, či by sa to celé nedalo robiť inak. Nebojte sa však byť v tejto téme prvou lastovičkou. Vzdušné prúdy vyspelých trhov jasne ukazujú, že túto tému čoskoro privanie aj na Slovensko. A to vás zoberie na cestu od Zero ku Hero.
 Takto vyzeral žartík, o ktorí sme sa pokúsili pár rokov dozadu pri jednej z návštev McDonaldu. Dávať do súvislosti Big Mac a Big dáta bola naozaj roztopašnosť. Koniec koncov, ako to celé dopadlo sa dočítate úplne na konci tohto blogu. To, čo vtedy vydalo na drobný žartík, však dnes už nie je na smiech. Aj tak priamočiary biznis ako nepochybne fast-food je, totiž začína objavovať zákutia dátovej analytiky a práce s umelou inteligenciou. Jednoznačným dôkazom tohto trendu je nevídaná akvizícia, ktorú sa sieť reštaurácií McDonald’s rozhodla realizovať.
Takto vyzeral žartík, o ktorí sme sa pokúsili pár rokov dozadu pri jednej z návštev McDonaldu. Dávať do súvislosti Big Mac a Big dáta bola naozaj roztopašnosť. Koniec koncov, ako to celé dopadlo sa dočítate úplne na konci tohto blogu. To, čo vtedy vydalo na drobný žartík, však dnes už nie je na smiech. Aj tak priamočiary biznis ako nepochybne fast-food je, totiž začína objavovať zákutia dátovej analytiky a práce s umelou inteligenciou. Jednoznačným dôkazom tohto trendu je nevídaná akvizícia, ktorú sa sieť reštaurácií McDonald’s rozhodla realizovať. mohli naraziť). Možno ste si všimli, že väčšina ponúk a pútačov v reštauráciách tejto siete sa za nedávne obdobie premenila na digitálne displeje. Táto zmena umožňuje nie len efektívne urýchliť výmenu nových ponúk za tie staré, ale umožňuje aj personalizovať ponuku pre konkrétneho zákazníka. Iste, pri štandardnom objednávaní priamo pri pulte v reštaurácií to zmysel nemá, lebo „personalizovaná“ ponuka by miatla okolo stojacich. Ale pri drive-in to možné je. Ako to celé teda bude fungovať?
mohli naraziť). Možno ste si všimli, že väčšina ponúk a pútačov v reštauráciách tejto siete sa za nedávne obdobie premenila na digitálne displeje. Táto zmena umožňuje nie len efektívne urýchliť výmenu nových ponúk za tie staré, ale umožňuje aj personalizovať ponuku pre konkrétneho zákazníka. Iste, pri štandardnom objednávaní priamo pri pulte v reštaurácií to zmysel nemá, lebo „personalizovaná“ ponuka by miatla okolo stojacich. Ale pri drive-in to možné je. Ako to celé teda bude fungovať?