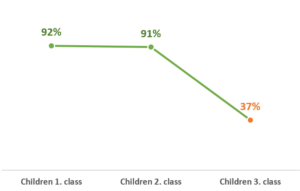
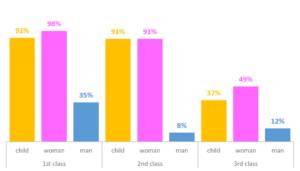
Artificial intelligence (AI) and its applications are mushrooming in more and more areas of our lives. To read economic magazine without stumbling across AI article becomes almost impossible. As my Grandma used to say: “I open the fridge and I fear AI jumping out if. (which, by the way, happens too). If you possess a bit of critical thinking, you may be revisiting the thought “But why, for God sake?!”
You may have found out yourself that professional blindness is a strong phenomenon. It has not spared myself either. On daily basis, it my job to think how to improve machine learning and predictive analytics, so that it brings value to our company. Therefore the “poke’’ on why are we embracing the AI so heavily, has come from unexpected source. Our talk has been flowing continuously, when striking and well-aimed question has aroused: “Why, on earth, do we humans invest so much money to create something that can dwarf us? Where would human race progress, if all those billions were actually aimed at developing the human intellect?” I took a breath before launching the tirade on clear AI benefits and … then I swallowed the sentence. There is a point in this thought. Is there actually alternative to AI?
It was beautiful autumn afternoon and we have been walking our dogs in one of the parks of Bratislava, Slovakia. My wife is respected, seasoned soft skills trainer for large global company. I have been explaining to my wife the fascinating essence of AlphaGo victory over the GO game world champion. She silently reflected on the story, then stopped for a while and turned to me: “Why, on earth, do we humans invest so much money to create something that can dwarf us? Where would human race progress, if all those billions were actually aimed at developing the human intellect?” As any husband, unthinkable ideas are something, that one get used to from our beloved ones. But just before I spit the answer, I had to admit to myself I never thought this way. Existence and development of AI seemed to me natural same way as lumberjack probably does not think about paper recycling.
But think provocative idea kept on itching me. Consequently, I started to think about what alternative to AI we REALLY have? Why are we so eager to advance with AI anyway? So, let’s do a deep-dive together:
The original motivation
At the very beginning of the computers (and their usefulness) was the desire to count things, where humans can do mistakes. Mainly the complex calculations with high precisions (too many digits) are the primary targets. While, back then the only alternative had been paper and column of figures to add together. To be fair, it is difficult to object to his motivation, as we all know, that humans are indeed error prone. But to keep the dispute entirely fair, one should add “humans without any training are error prone”. One team taught me this lesson during my time working for Postal Bank, where I had the privilege to lead Client and processing centre. The group of a dozen middle-aged and senior ladies faced every single day the staggering task to retype 10 000 hand-written, paper money orders per employee into transaction system. Even though that this was very monotonous (maybe even dull) task – imagine you retype digits from paper to screen 8 hours a day, every day – their error rate was hard-to-believe 1 in 100 000. If you apply 4-eyes check to this process, you are at level of 1 in 10 million. That beats most of the computer managed processes I have ever seen. So, the error rate is certainly not the ultimate excuse for AI.
Paradoxically, the second motivation for strong boost in computer intelligence was the effort to hide something from the others. Encryption and breaking the cyphers were strong pull for computer science. The entire storing of Turing is great testimony to it. What we should note here, that this was also first attempt to use AI against the human. In recent security situation, it is difficult to argue against privacy of the communication or interception risk. More idealistic souls would probably stand to “More human trust would bread less encryption needs.” But obviously this is more difficult issue, as already decades a go we needed sealed envelopes to send even the banal news from our lives. The encryption need springs from ultimate human longing to manipulate other. And there the humanity is not keen (for centuries) to give up.
That brings us to the third motivation for human race to massively introduce computer science to their lives: Comfort. Similarly, as other machines also the computers tuned-in to human comfort seeking passion. Obviously, human can also try solve numeric optimization by plugging in 20 000 times the values to set of equations. But why would the mortal to bother with this, if the computer can dully take this task for him. The sad part of the story here is the fact that computers were not cleverer at solving the equation, it was pure brute force. (it was the speed by which the computers could enter too many wrong solutions before stumbling across a correct one). While I have met several genius humans, who were talented to snap computations in their heads. The younger crowd maybe puzzled by info that there is even “paper-based” way to calculate any square root, so one can really do it without reaching for calculator.
True, even with supreme training, none of the humans would match the millions per second calculations done by modern computer processing units (CPUs). But to stay on a fair ground, even the most advanced AI has come to the point where more computational power is not gained mainly by getting better and better CPUs, but rather tapping into parallelization. Thus, if you realize that only fraction of percent of humans are earning their bread with daily calculating something, it is safe to say we have not really tried the full power of human parallel power before (somewhat eagerly) embracing the artificial intelligence. In this sense the cheeky question of my wife holds: Why humans decided to build better and better electron box rather than try to improve the intelligence of our fellow humans?
Last nail to coffin
All of the above trends would be still revertible if not for one more important human decision made. For decades the engineers and scientists were putting their brainpower to question of how to replace as much of the human labour by robots as possible. At the peak of the 90s their succeeded in this effort and they – well – start to look left-and-right for next mission to conquer. Research centres all around the world jumped on simulating human senses and human line of thought.
 However, to succeed in this, first the machines needed to copy our cognitive functions. So, step by step, we taught computers to detect the voices and images same way we, humans, do that. Once they mastered that, we instructed them how to realize the basic tasks (like continuously check on temperature in the room and if below threshold, put the heating on). But as we do not have not entire understanding of our thinking processes, soon we ran into the problem that more complex tasks cannot be rewritten into chain of what-if instructions. So, we let the computers try (and fail) as many time as the machine (repeatedly) mimicked the desired result. Thus, machines derived rules for things we ourselves were unsure of (and thus we struggle to validate as general principles). Areas, where humans were not able to generate reasonable number of examples for machines’ try-and-fail learning, are still unmastered by computers.
However, to succeed in this, first the machines needed to copy our cognitive functions. So, step by step, we taught computers to detect the voices and images same way we, humans, do that. Once they mastered that, we instructed them how to realize the basic tasks (like continuously check on temperature in the room and if below threshold, put the heating on). But as we do not have not entire understanding of our thinking processes, soon we ran into the problem that more complex tasks cannot be rewritten into chain of what-if instructions. So, we let the computers try (and fail) as many time as the machine (repeatedly) mimicked the desired result. Thus, machines derived rules for things we ourselves were unsure of (and thus we struggle to validate as general principles). Areas, where humans were not able to generate reasonable number of examples for machines’ try-and-fail learning, are still unmastered by computers.
Where are we (doomed) to go
From above stated facts, it is clear that AI rise was not inevitable consequence of the history and that this train has been set on its track (and cleared to go) by us, mortals. First impatience to our own mistakes, later suspicion and finally laziness to repeated mental tasks. Without being pathetic, I am not that sure we always used all the options to “match” the AI.
Now we have progressed even one step further and launched the development of universal artificial intelligence (UAI) that can zoom out to think if it thinks properly. There are already several ways, how to teach computers to copy human approaches. Yes, in some areas, it is still not clear, how to teach computers to beat us in that domain. But all it takes is just few research projects that compile large enough set ( equals millions) of of the annotated examples and machines will tediously crack their way through these obstacles. If you look from any angle, “the genie is out of the bottle” and the machines’ feat to rival the humans is imminent. So what options are left with?
The most naïve option would be to try to fully stop. There are still some areas that machines cannot do and if we, humans, do not show them what is right and wrong in that areas, they will not master this skill (e.g. human empathy). But reading this line again after myself sounds equally silly as the rallies to damage machines taking the human labour at outbreak of industrial revolution. Therefore, I deem this scenario to be highly unlikely.
The secon d option is to use artificial intelligence to reversely strengthen the human development. If you remember 1996, when Gary Kasparov was paying the chess against the Big Blue computer, he lost his first game of the best-of-five match. Gary, back then, did not have any human rival, who would bring him to the rim of losing the game. However, under extra stimuli of the super powerful computer opponent, he managed to top his skill yet even more and he defeated the computer in overall match score. Therefore, if we use AI to stimulate human development, in some areas we could (at least temporarily) reclaim the “throne” of intelligence. However, that would require to add extra layer of AI that explains to human the principles it has “learned itself”.
d option is to use artificial intelligence to reversely strengthen the human development. If you remember 1996, when Gary Kasparov was paying the chess against the Big Blue computer, he lost his first game of the best-of-five match. Gary, back then, did not have any human rival, who would bring him to the rim of losing the game. However, under extra stimuli of the super powerful computer opponent, he managed to top his skill yet even more and he defeated the computer in overall match score. Therefore, if we use AI to stimulate human development, in some areas we could (at least temporarily) reclaim the “throne” of intelligence. However, that would require to add extra layer of AI that explains to human the principles it has “learned itself”.
The third alternative to AI dominating the humans is to merge AI into human intelligence. In other words, to find a biologically sustainable way for our brain (maybe via implants) to be extended for additional layer of all that AI has learned. With substantial risk of overgeneralization this can be parallel to you extending the camera memory by plug-in memory card. This way, any AI advancement would immediately be translated into human potential as well. The principle certainly carries some moral risks as well (who decides on what will be programmed into heads of the others), but also prevents the doom scenario of machines taking the rule over the humans.
One way or the other …
Despite the encouragement from previous paragraphs, I am afraid that I do not foresee the happy-end scenario in this AI story. To tip the hand of intelligence dominance scale back a bit towards human race, we would need 2 essential ingredients: A] source of information that is independent of computer infrastructure (otherwise, later in time we would be not able to tell the difference between info computer generated and the reality just chronicled into computer). And add to that also B] quick way of replicating of all knowledge among human-fellows, even across the generations. Contrary to machines, that need to learn all our knowledge just once, we, humans, need to relearn the knowledge with every new generation again. In both required dimensions there exist the theoretical approaches, but their implementation is not to be seen anywhere near ahead in forthcoming years to come.
Therefore, as the AI development is at its full speed, we should be ready to face singularity scenario (machines surpassing our entire intelligence) as the most probable scenario. Including all the social implications arising from this. (mainly wave of unemployment and career progression crises that we aim to discuss in more detail on this blog soon). Because, all in all, with AI taking over there is much more swallow than our intelligence pride.

 In my presentation, titled “Feature engineering – your trump card in Machine Learning” you will find out what are the 2 key reasons for feature engineering future. First explains how variables can become competitive advantage of your models. The second one goes even beyond that and hopefully opens your eyes why Feature engineering might be actually essential for Data Scientists’ future job security.
In my presentation, titled “Feature engineering – your trump card in Machine Learning” you will find out what are the 2 key reasons for feature engineering future. First explains how variables can become competitive advantage of your models. The second one goes even beyond that and hopefully opens your eyes why Feature engineering might be actually essential for Data Scientists’ future job security.








 Step 3: Look for real Data Science leader in real Data Science team.
Step 3: Look for real Data Science leader in real Data Science team.