Ak to so svojou kariérou dátového analytika myslí človek vážne, prirodzene ho začne priťahovať myšlienka pracovať pre jedno z odvetví, kde je rast dát najrýchlejší. Tam sa totiž „pečie“ koláč budúcnosti. Presne preto boli „magnetické“ najprv telekomunikačné firmy a banky v 90tych rokoch, po roku 2000 E-commerce a za posledné desaťročie najmä sociálne siete. Viete však čo je “v trúbe“ na to najbližšie obdobie?
Mnohí by možno odpovedali, že najlepšie miesto pre vybláznenie sa „dátového analytika“ musí byť predsa Google. Veď, ruku na srdce, čo vlastne o nás Google nevie? (odpoveď TU, 16min:40sek ) Nuž, možno by vás prekvapilo, že keby sme zobrali jednotlivé služby Google samostatne jednu po druhej, tak existujú firmy, ktoré majú oveľa viac dát ako tieto produkty Google. Začínate krútiť hlavou? Možno čas poopraviť si mienku.
Fenomén Búrka
Ak chcete správnu odpoveď uhádnuť sami, tak tu sú pre vás ešte dve indície (otca Furasa z veže): 1) Skupinové aktivity generujú vždy viac dát ako obsah generovaný jednotlivcom; 2) Dáta o pohybe (video) poskytujú oveľa viac premenných ako statické obrázky, zvukové stopy alebo len čistové textové údaje. Ak si trúfate uhádnuť, čo za odvetvie to je, tak sa nachvíľu tu zastavte v čítaní (ďalší odsek odkrýva správnu odpoveď). My ostatní ideme priamo na to.
Digitálnymi hrami aktuálne máva fenomén Fortnite. Táto hra má aktuálne približne 200 miliónov pravidelných používateľov (MAU = monthly active users) a v každej sekunde sa ju hrá![]() približne 8.5 milióna hráčov súčasne po celej planéte. Keďže ide o multi-player hru, jej tvorcovia (štúdio EpicGames) musia dôkladne ukladať, čo každý z hráčov urobil. Pretože práve vzájomné interakcie hráčov sú to, čo rozhoduje o tom, či Vaša postava prežila alebo ste z hry vypadli. Vo Fortnite totiž (pod rúškom prichádzajúcej kataklizmickej búrky) sa neustále zužuje herný priestor a tak prichádza k nevyhnuteľným stretom jednotlivých postáv (hráčov) a potvrdeniu, že Darwin sa predsalen nemýlil.
približne 8.5 milióna hráčov súčasne po celej planéte. Keďže ide o multi-player hru, jej tvorcovia (štúdio EpicGames) musia dôkladne ukladať, čo každý z hráčov urobil. Pretože práve vzájomné interakcie hráčov sú to, čo rozhoduje o tom, či Vaša postava prežila alebo ste z hry vypadli. Vo Fortnite totiž (pod rúškom prichádzajúcej kataklizmickej búrky) sa neustále zužuje herný priestor a tak prichádza k nevyhnuteľným stretom jednotlivých postáv (hráčov) a potvrdeniu, že Darwin sa predsalen nemýlil.
Práve potreba dokumentácie pohybu všetkých postáv a ich vzájomných interakcií robí z hry neskutočného chŕliča dát. Predstavte si to ako (dátové zakódovanie) videa pohybu 8.5 milióna ľudí súčasne. Fascinujúce, nie? Podľa informácií Amazon Web Services (AWS), ktorí spravujú dátové úložiská pre túto hru, objem dát dosahuje hodnotu 95 PetaBytov (a stále rastie). To je veľkosť porovnateľná s Google Indexom na vyhľadávanie všetkých dostupných stránok internetu. Napadlo by vám, že hra môže byť väčšia ako Google. Áno, vyhľadávanie je len jedna zo služieb Google, ale Fortnite je rovnako len jedna z desiatok tisíc digitálnych hier. (Aj keď uznávam, momentálne asi najväčšia)
Nové magnetické odvetvie
Online hry sú naozaj fenomén. Len v Spojených Štátoch Amerických rástli v 2018 tržby v hernom priemysle úctyhodným tempom 18% za rok (podľa údajov asociácie Entertainment Software Association (ESA) ). Vďaka tomuto rastu patrí herný priemysel medzi jedny z najrýchlejšie rastúcich odvetví vôbec a len v USA zamestnáva viac ako 200 tisíc ľudí. Ako dokáže toto odvetvie tak rýchlo napredovať?
Po niekoľko desaťročí sa herný priemysel správal podobne ako filmárske štúdia. Veľký počet navzájom (nepriamo) súťažiacich filmových teamov vychrlilo na trh stovky filmov s nádejou, že niektoré z nich budú hitmi. Väčšina sotva zarobila na výrobné náklady (a honoráre pre hercov). Ale zopár z nich boli zásahy do čierneho, ktoré zarobili stovky miliónov dolárov a tak pokryli diery „po prepadákoch“. Áno, aj herné štúdia produkovali ročne stovky až tisíce hier rôznych žánrov. A potom sa modlili, aby si hry našli dostatočné publikum. Herný priemysel tak v tomto období bol odkázaný na vzostupy a pády, ich ekonomické výsledky pripomínali skôr húsenkovú dráhu, než stabilný rast, aký vidíme dnes. Ako to, že dnes vykazuje dlhodobo rast a navyše rast ekonomicky tak nadpriemerný?
Tou podstatnou ingredienciou, ktorá sa zmenila, sú práve dáta. Počítačové hry sú totiž dnes dizajnované tak, že pre výrobcu uchovávajú informácie o tom, ktoré časti hry boli pre používateľov atraktívne či nudné, príliš (až nezdolateľne) náročne alebo naopak nezáživne ľahké. Postupným sledovaním preferencií hráčov sa vývojári naučili nakalibrovať vývoj príbehu v hre tak, aby udržala hráčov pred obrazovkou čo najdlhšie. Tým dokázala zvýšiť celkové publikum hráčov. Z dúfania v hity sa stala cielená fabrika na úspešné hry. Tento jav zarovnal „kopce a doliny“ v úspechoch herných štúdií. (Teda minimálne tie doliny, kopce ako Fortnite sa stále kde tu objavia). To však nebol jediný efekt dát v hernom priemysle. V skutočnosti dáta priniesli tomuto odvetviu dva ešte podstatnejšie tromfy.
Ďalšie dva tromfy
Pôvodný biznis model sa snažil celú hodnotu hry skasírovať od potenciálneho hráča pri kúpe samotnej hry. To je však, ako keby ste museli zaplatiť za dom bez toho, že by ste sa v ňom detailne poprechádzali, prípadne strávili pár nocí. Tento prístup podnecoval softvérové pirátstvo, lebo na to, aby ste sa hru mohli hrať do životne vám stačilo dostať sa iba k jej cracknutej verzii. (Predstavte si, že by sa dom aj s pozemkom stáli doživotne vašimi iba tým, že by ste si od zámočníka nechali urobiť falošnú kópiu kľúču. Mnoho ľudí by tomuto zjavnému pokušeniu neodolalo. A tak to bolo aj s hrami).
Zbierané dáta o tom, ako napredujú hráči v jednotlivých častiach hry, však umožnili herným štúdiám do častí príbehu, kde uviazlo viac hráčov, umiestňovať „platené skratky“. Za pár eur vám hra ponúkla nápovedu, chýbajúce zdroje na ďalšie budovanie alebo nejaký predmet či schopnosť pre Vašu postavu. Zrazu sa celá šachová partia okolo speňaženia hry otočila: Bolo to v záujme hráča samotného zadovážiť si túto platenú pomoc. Je to, ako keď chcete pred letom do domu namontovať klímu. Prežijete aj bez nej, ale v horúcom lete Vás to bude stáť viac síl. Klimatizáciu si však už nemôžete pričarovať sfalšovaným kľúčom, tú už musíte riadne nechať nainštalovať a zaplatiť. Tento druhý dátový vplyv sa ukázal ako omnoho podstatnejší, lebo ako aktuálne štatistiky ukazujú, že až 43% z celkových príjmov hier bežiacich na mobiloch či tabletoch generujú práve rozšírenia a položky dokúpené priamo v aplikácií počas hrania.
Tretím tromfom, ktorý priniesli dáta do herného priemyslu, je tvorba a testovanie nového obsahu. Mať úspešnú hru ako Angry Birds, či niektorý z podobných hitov, znie ako požehnanie. Milióny ľudí sa hrajú vec, ktorú ste vy raz naprogramovali, a na účte vám doslova len cinkajú nové a nové peniaze.
 Takto ružovo to vyzerá však iba ak ste majiteľom firmy. Už menej optimistický odtieň to pre vás má, ak ste vývojárom, ktorý musí danú hru programovať. Podľa údajov zverejnených na konferencii NOAH LONDON 2019, obrovský dopyt desiatky miliónov hráčov hry Andry Birds Dream Blast spôsobuje, že firma musí vytvoriť každý týždeň ďalších 40 nových levelov hry. Ak sa vám z toho netočia ešte panenky, tak vám to skúsim rozmeniť na drobné: Priemerný pracovný týždeň má 5 x 8 = 40 pracovných hodín. Developerský team tejto hry musí každú pracovnú hodinu vymyslieť, naprogramovať, otestovať a nasadiť nový level. Každú pracovnú hodinu! Iste môžete mať armádu programátorov, ktorí dokážu pracovať paralelne tak, aby stihli novú úroveň hry za danú hodinu vymyslieť a naprogramovať. Ale ako dokážete v rámci danej hodiny aj hru dôkladne otestovať, keď jedna hra daného levelu si môže vyžadovať niekoľko minút hry? Aj keby ste mali armádu 100 testerov, spolu s vývojom hry by si ju stihli zahrať do hodiny tak možno 500-600 krát, čo je pramálo na to, aby ste pochopili, ako budú vnímať hru milióny rozličných používateľov. A tak prišla opäť na rad úloha dát.
Takto ružovo to vyzerá však iba ak ste majiteľom firmy. Už menej optimistický odtieň to pre vás má, ak ste vývojárom, ktorý musí danú hru programovať. Podľa údajov zverejnených na konferencii NOAH LONDON 2019, obrovský dopyt desiatky miliónov hráčov hry Andry Birds Dream Blast spôsobuje, že firma musí vytvoriť každý týždeň ďalších 40 nových levelov hry. Ak sa vám z toho netočia ešte panenky, tak vám to skúsim rozmeniť na drobné: Priemerný pracovný týždeň má 5 x 8 = 40 pracovných hodín. Developerský team tejto hry musí každú pracovnú hodinu vymyslieť, naprogramovať, otestovať a nasadiť nový level. Každú pracovnú hodinu! Iste môžete mať armádu programátorov, ktorí dokážu pracovať paralelne tak, aby stihli novú úroveň hry za danú hodinu vymyslieť a naprogramovať. Ale ako dokážete v rámci danej hodiny aj hru dôkladne otestovať, keď jedna hra daného levelu si môže vyžadovať niekoľko minút hry? Aj keby ste mali armádu 100 testerov, spolu s vývojom hry by si ju stihli zahrať do hodiny tak možno 500-600 krát, čo je pramálo na to, aby ste pochopili, ako budú vnímať hru milióny rozličných používateľov. A tak prišla opäť na rad úloha dát.
Keďže herné štúdia majú k dispozícií obrovské zásobníky dát o histórii hrania tejto hry (a iných podobných), vedia vyprofilovať typické profily hráčov, ktoré sa nachádzajú v celej enkláve fanúšikov hry. (Niekto hrá len pre pocit, že dokáže zdolať daný level, niekto sa neuspokojí kým nedosiahne čo najväčší počet bodov, niektorým vôbec nejde o ukončenie levelu, len sa zabávajú na rôznych nezdarných riešeniach hlavolamu, …) Pre každý typ fanúšika hry následne herné štúdio natrénuje neurónovú sieť (pomocou reinforcing learning), ktorá dokáže simulovať hranie práve daného typu užívateľa. Následne sa v cloud prostredí (ako AWS) vytvorí mnoho kópií virtuálnych hráčov (tisíce pre každý typ hráča), ktorým sa odovzdá novo nadizajnovaný level hry a spustí sa ich hranie. Firma tak získa obrovský počet spätných väzieb o tom, akú odozvu bude mať práve navrhnutý nový level hry pre jednotlivé skupiny hráčov. Čo je podstatné, že takéto digitálne dátové testovanie je prudko škálovateľné, keďže nie ste limitovaný tým, koľko rôznych typov hráčov máte alebo koľko rôznych levelov ste vytvorili.
Tak čo vy?
Tým sa sled dátových vplyvov na herný priemysel uzatvára do silnej, čoraz viac sa rozpínajúcej špirály. Je teda jedno, či túžite robiť dátovú analýzu hráčov, jednotlivých komponentov hry alebo vás viac fascinuje hľadanie vhodných škáročiek na in-app nákupy, či parametre nových úrovni hry. V hernom priemysle sa naozaj aktuálne črtá mnoho zaujímavých analytických príležitosti. Preto, ak pracujete v niektorom z dátovo už nudných sektorov (banky, utility, poisťovne, …) možno je čas rozhliadnuť sa aj po hernom sektore. A vôbec nemusíte baliť kufre, veď len na Slovensku pôsobí viac ako 20 herných štúdií a ročne u nás vychádza viac ako 70 nových hier. Firmy ako PIXEL FEDERATION si pomaly získavajú rešpekt aj ostatných odvetví a predstavujú dotyk s Európskou špičkou herného priemyslu. Ak by ste predsa boli ochotní zbaliť ten kufor, za hranica sú možnosti takmer neobmedzené. Tak čo? Idete sa radšej pohrať s dátami alebo s Googlom?
 V rodine, kde by ste zahodili všetky účtenky a vyčiernili časť emailových adries (napr.
V rodine, kde by ste zahodili všetky účtenky a vyčiernili časť emailových adries (napr.  adresáta. Ak by sme chceli byť striktní, tak by musel ešte prísť sused a poprehadzovať darčeky tak, aby nik nevedel, kto v akom poradí darčeky pod stromček položil.
adresáta. Ak by sme chceli byť striktní, tak by musel ešte prísť sused a poprehadzovať darčeky tak, aby nik nevedel, kto v akom poradí darčeky pod stromček položil. Dosiahnuť
Dosiahnuť  Pravdepodobnosť určitého javu však nie je jedinou vecou, ktorú musíme v bežnom živote odhadovať z pomerne nízkeho počtu vstupných dát. Osobitnou oblasťou ľudských odhadov je snaha o odhad budúceho trvania, najmä pre veci ktoré už bežia. Koľko bude nízka nezamestnanosť, ktorú teraz máme? Koľko rokov bude žiť ešte Kim-Čong-Un? Ako dlho bude ešte fungovať Facebook?
Pravdepodobnosť určitého javu však nie je jedinou vecou, ktorú musíme v bežnom živote odhadovať z pomerne nízkeho počtu vstupných dát. Osobitnou oblasťou ľudských odhadov je snaha o odhad budúceho trvania, najmä pre veci ktoré už bežia. Koľko bude nízka nezamestnanosť, ktorú teraz máme? Koľko rokov bude žiť ešte Kim-Čong-Un? Ako dlho bude ešte fungovať Facebook? Nech táto úvaha znie akokoľvek logicky, nie je v skutočnosti pravdivá. Ak sa opätovne začítate, do
Nech táto úvaha znie akokoľvek logicky, nie je v skutočnosti pravdivá. Ak sa opätovne začítate, do 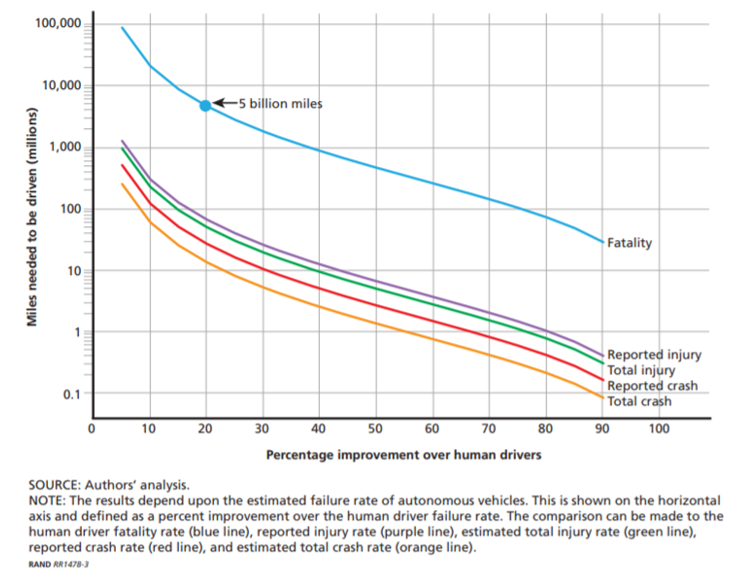
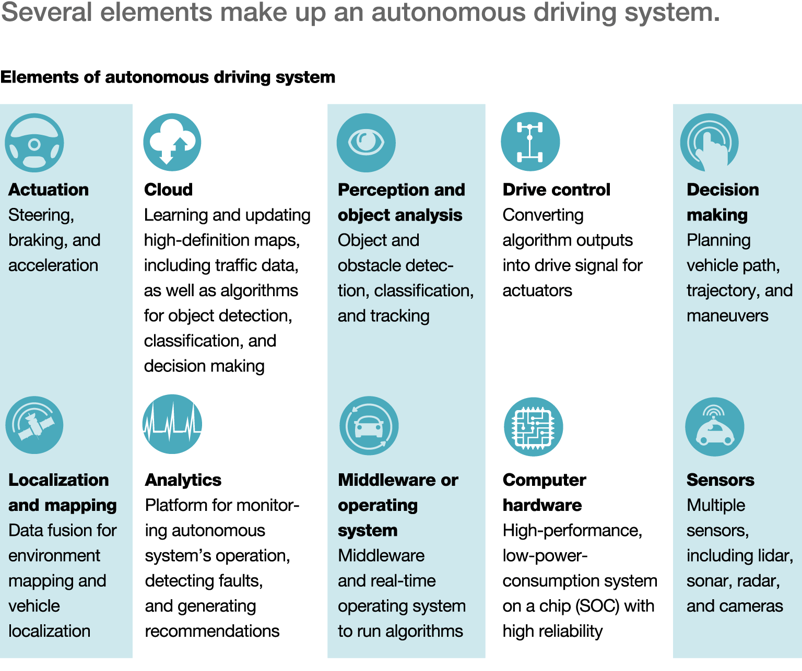
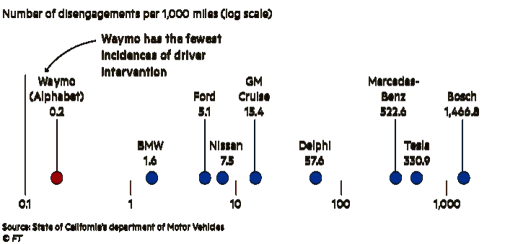
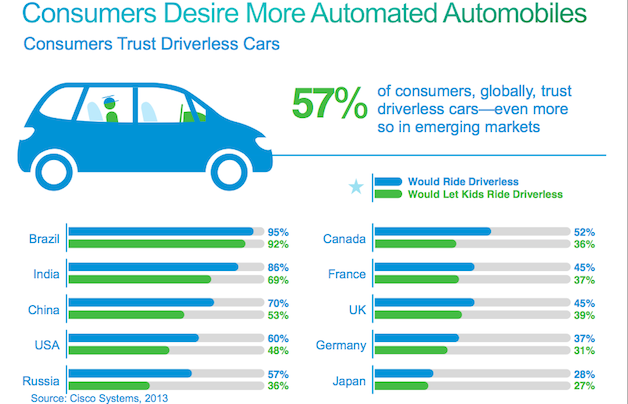 Keďže povedomie o príchode autonómných áut je u nás na Slovensku, žiaľ, pomerne slabé., občas dostávam aj otázku: A kto vlastne bude chcieť tými samojazdnými autami cestovať? Dôverujú vôbec ľudia tomuto vynálezu? Solídny výskum na Slovensku zatiaľ nebol realizovaný (alebo minimálne zverejnený), ale čo to napovie postoj iných krajín. Pre mňa zaujímavé je, ako rozličné sú postoje naprieč kontinentami. Európa je zatiaľ chladnejšia k tejto téme ale treba povedať, že Európa má zase jednu z najnižších nehodovostí áut na svete, takže argument záchrany ľudských životov tu nie je až tak plastický (alebo je pre neho latka postavená veľmi vysoko). Štúdia pochádza od spoločnosti CISCO a bola realizovaná už v roku 2013, približne v čase, keď Tesla predstavila Model S:
Keďže povedomie o príchode autonómných áut je u nás na Slovensku, žiaľ, pomerne slabé., občas dostávam aj otázku: A kto vlastne bude chcieť tými samojazdnými autami cestovať? Dôverujú vôbec ľudia tomuto vynálezu? Solídny výskum na Slovensku zatiaľ nebol realizovaný (alebo minimálne zverejnený), ale čo to napovie postoj iných krajín. Pre mňa zaujímavé je, ako rozličné sú postoje naprieč kontinentami. Európa je zatiaľ chladnejšia k tejto téme ale treba povedať, že Európa má zase jednu z najnižších nehodovostí áut na svete, takže argument záchrany ľudských životov tu nie je až tak plastický (alebo je pre neho latka postavená veľmi vysoko). Štúdia pochádza od spoločnosti CISCO a bola realizovaná už v roku 2013, približne v čase, keď Tesla predstavila Model S: