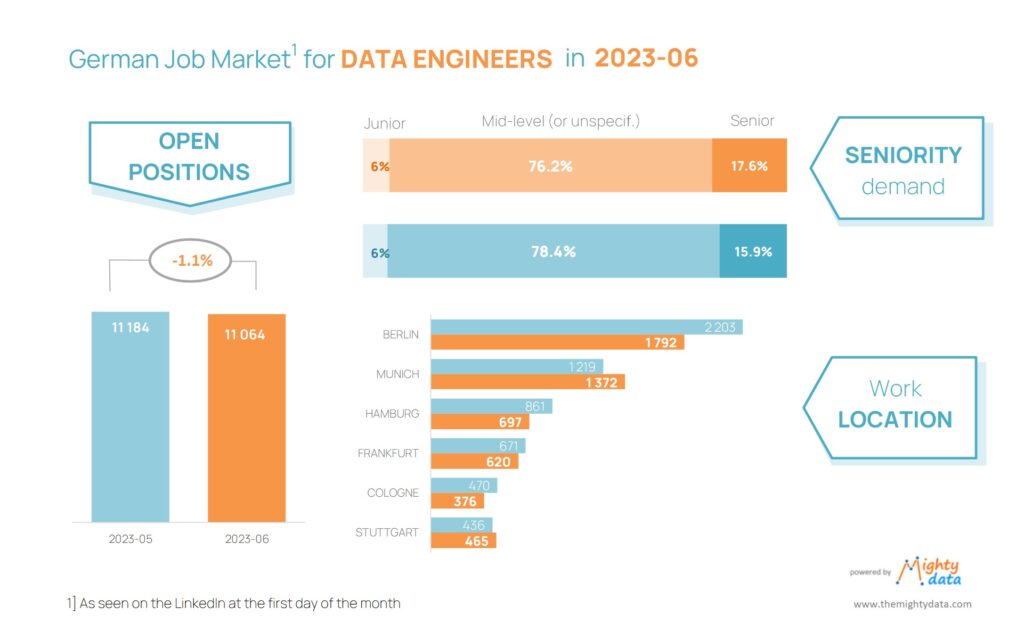
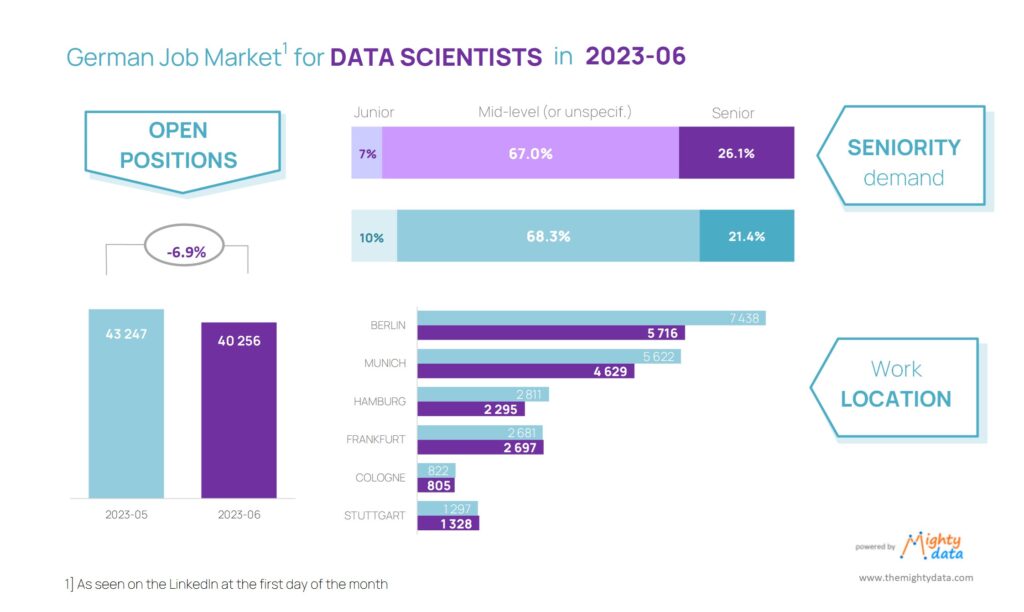
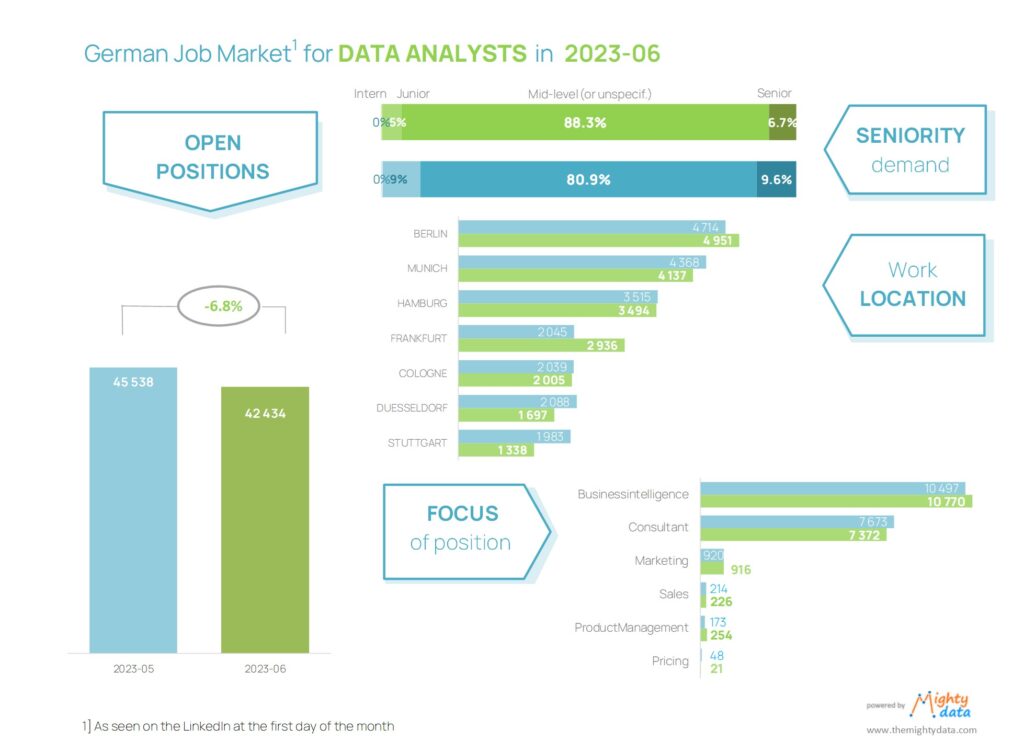
We often do not believe how broken things are, before we experience them ourselves. So was the case of the Labor market for (AI roles). You might be puzzled, because what more hot industry than Artificial Intelligence can you image to look for job?! Well that was my piece of mind as well, until I was subjected to 400+ job processes over the course of 6 months,
that many are bizarre to say the least. And they are completely orthogonal to your skills or weak points. They are simply HR habits and processes born before AI era and now got completely out of sync with reality.
As I didn’t want to drop these things just into well-of-disbelief for myself, I decided to release it as Wicked Hiring Advent Calendar. You can read day after day, where (AI/Tech) hiring stands now. And how not to depress yourself further, because most likely, what you go through is not your fault. And just for the record, over the 6M I describe here, I came across (turned down) and finally accepted suitable job. But the noise to signal ration is disgustingly terrible. Hiring industry is really ripe for major disruption. Read on why
(too speed up reading, sequels of this series are ordered in descending order)
PART | 12 | POLAND’s and UKRAINE’s hiring self-defense (and what you can learn from that)
When hiring we aim to find somebody who fits in. But what if fitting in means actually screening some totally unwelcome candidates? How to do that without crossing line into discrimination? Let me share with you interesting case I experienced lately.
Most of us live in peaceful and progressive environments where you appreciate any new candidate (at least for the first few hundreds), as the more choice you have the better you are off you are to pick right choice (assuming your hiring process is not broken). But what if your country (or your biggest neighbor) are at war and you want to prevent the adversary representatives to infiltrate your key enterprises vital for the economy?
This is exactly the situation that Ukraine (and also Poland) are facing. Being assaulted by Russia, your territory and fellow Ukrainians being killed, top management of Ukrainian (national) enterprises would not like to fall victim to enemy’s spies infiltrating the production lines (and potentially attempting sabotage or technology espionage). Situation is even more precarious with Poland, that is strong ally of Ukraine, has accepted millions of war refugees (who now work in collectives), and is not at war itself. Being a EU member state and in explicit war state, you cannot screen people around their nationalities, in fact you cannot even ask for nationality of the person as mandatory application field. That’s downright discriminatory. So, what do you do?
I stumbled upon this accidentally but found it clever way. Linked In “Easy apply” process allows hiring company to define set of additional questions that all candidates need to answer before their application is filed. Usually companies use this to filter down on those who meet certain expertise criteria (“How long have you worked with GenAI?”) But some Polish and Ukrainian companies got clever by using this to also negatively select. On quite some Polish LinkedIn job ads there popped question “What is your level of mastering Russian?” What is not obvious that the “advanced” or “native speaker” does not get you ahead of the other candidates (as usually for these questions), rather it sends you down the priority list.
Why do I mention this? If you are hiring company and you have desirable as well as undesirable criteria can be turned into candidates prioritization sorting, you just need to formulate them as positive statement (and use higher values as negative points). So keep that in mind when preparing your recruitment screening question.
PART | 11 | BREATH of 90’s (Terrible hiring sins that still prevail)
If you follow our Wicked Hiring Advent Calendar from start you already have been initiated into set of bizarre and out-of-sync with reality practices. But today we have special treat for you.
Round of 432 job application I ran through brought set of bizarre experiences. And when I say bizarre, I really mean it. If I did not come across these situations myself, I would not believe these things are still happening. So without further due, let’s jump directly into them.
Proving your CV wrong. This interview lasted almost 60 minutes, but had actually just one common theme. The person leading the interview was on mission to catch me lying in my CV. “How come your career starts with managerial role right away, what did you do really before your first managerial role? What does such a VP really do in his job? Here you have not been promoted for 3 years in row, what did you fail to do?” She did not find anything. I did. I found good reason to drop off the process.
Lying about their company role. I was invited to in-person interview. One of the participants introduced as “HR team member”. But I knew who she was, as I checked on LinkedIn the names and roles of people on calendar invite. She was CEO of the company in disguise, trying to pretend she was not one. What kind of culture is it signaling if CEO lies about her role in ordinary interview?
I have to see you 6 times. If hired role is stakeholder contact heavy, it makes sense for the candidate to meet different stakeholder groups for mutual chemistry and respect check. This usually makes the process longer, but with at least some decent reasoning behind. Now, some prefer dating to go slowly. Or very slowly. On our first meeting with CEO, who was also hiring manager for my role, I have been informed by the very CEO that he needs to see me 6 more times before he can decide if we can work together. When double checking, if I heard really correctly, I could not help myself asking: “But why do you need to make 6 distinct sessions?” I am quite sure you wouldn’t guess what the answer was: “After each of our meeting I have to sleep on it before I can talk to you again.” I told him that I would not like to kill that much of his time and I hereby withdrew my application. I was supposed to be hired there for large transformation project (run in extremely short time plan), that CEO was supposed to be leading himself. Sometimes it’s crucial to spot the issue already from the distance.
Attention test. Testing candidates for psychological profile or leadership style smells like sweet 90’s, but still might offer some insights for hiring manager about resilience or combativeness of person. So whenever I was asked to take some of those tests, I willingly let myself get tested. However, the crown jewel of ridiculousness was coronated when I have been asked to test for attention for top managerial position. Yes, you read well, they sit me in the room and let me go through exercise testing my reflexes and eye movements. After interview I rushed to double check if the role included leading not only team, but also train locomotive, too.
Hiring bottom-up. Over the time I learned to tolerate (or at least withstand) many ridiculous HR practices. However, there is one practice I truly don’t believe in and I walk away from any company trying to apply it in hiring process: Bottom-up hiring means that technical competence of candidate is tested by his future inferiors. In other words, employees pick their own boss. Tried 4 times, all 4 cases were disastrous, where people interviewing were specific niche experts and were asked to evaluate breadth of my technical skills. The most bizarre case of this was when I was supposed in new role to fire and rehire Data Science team because they were not bringing enough drive and motivation. After interview session with one of my potential subordinates I got feedback from the team that I was very change seeking and thus HR had to drop me as candidate. I just can still wrap my head around this, even few months later.
Cynicism of hiring managers. Hiring managers (especially the lax ones) got astonished by sudden AI entry into recruitment world. As shared in dedicated episode of mAIndset podcast, candidates leaned into AI usage faster, while hiring side was often sticking to pre-AI approaches. This resulted into companies hopelessly stick to hiring their steps (like take-home case-study) only to get mad at candidates who consulted AI on delivering of those assignments. But the worst aftermath of this duality is that hiring mangers got desensitized to what good or bad answer is. They simply got cynical about any solution that was more elaborate. I got assignment to prepare blueprint for line of new AI products . I swear to god, I spent 3 days working on it and have not consulted AI for single line of it. How surprised I was to receive harsh answer back citing “This meticulously elaborate, all thought through AI-built document disqualifies you from further hiring process.” Come again, please?
10 rounds recruitment. You can easily spot ridiculous approach to recruitment by the mere structure of the interview process for candidate. I went through one such occasion lately, when HR informed me on first interview there will be at total 10 recruitment rounds. I gathered courage to call the elephant in the room: With 10 rounds you end-up with B- or C-tier candidate. Because no truly great A-player would bother to run for 10 rounds.
PART | 10 | PANDEMIC of internal candidates and why you SHOULDN’T PREFER them
We opened this Wicked Hiring Advent Calendar series with showcasing candidate ghosting. If you missed that sequel, let me just remind us that 52% of the Tech job postings never receive any answer. Today we reveal one of the main reasons why this is the case.
When venture is born, team is rather small, many have to multitask and if you happen to be part of the initial team there will be new tasks of all kinds thrown your way. But as company growth to corporation, roles get specialized and team bubbles into three-four digits of confederates. That’s moment when even meticulous skills mapping might not cover the exact inventory of what your employees can do.
That leads to “what if” hope/uncertainty on if newly opened role might potentially have match with some existing employees past experience. Combined with “time greed” (we save 2-3 months of waiting for candidate and onboarding) and (declarative) employee equal chances (mandating for any role to be officially open for both internal and external candidates) you end up with large share of roles where internal candidates (or their referrals) are meeting the external round. That is the mother of disaster.
You might be surprised to hear rant against internal candidates, but hiring teams turned it into ridiculous and counter productive practice. Firstly, opening ANY role both internally and externally (without even second thought if we may have chance for relevant candidate) is pure negligence. If company wants to build SW development team with specific coding language or you need to hire first cyber security expert, how likely are you to find internal candidate?
Second issue is with “Internal candidate preference”. What are you here optimizing for? Aren’t you looking for best possible match? Your internal pool is statistically inevitably inferior to whole world out there. So if you prefer internal candidates you are intentionally limiting yourself to less promising pool.
Thirdly, internal candidates are never through the same scrutiny as external candidates. Usually single meeting with hiring manager and some internal cross reference talk with existing superior of the candidate is good enough. Compare this to 5+ rounds of checks for external candidates, including past jobs reference calls. As a result, internal candidates are often hired more on “trust and vibe feeling” than expert rigor.
Finally, some argue that you save onboarding time. This is probably one of the biggest misconception. Filling the role with existing employee might optically save you time of explaining systems and data used in company, but what you don’t see that this internal candidate probably never worked on what you intend to do. So as much as (s)he will not need to get explained how to apply for vacation or which table to query, they will learn by attempting the actually challenge. The best way to explain is “If you need to undergo knee operation, would you like to be operated by professional surgeon from neighboring hospital or rather by internal gynecologist, that knows where the operation room and canteen in this particular hospital is?”
All this for gain of what exactly? Some declare speed. But let’s be honest, how many times is role so critical that 2 months waiting for great candidate is deal breaker? Others argument with hiring costs saving, but this is self-illusion. Because, if somebody jumps from internal role A to internal role B, you still need to hire for A (most of the cases). So very often it’s just hiring manager (or HR team) trying to make their lives easier by cutting corners.
Don’t get me wrong, I am all for internal promotions and development. But it needs to be intentional. Company should proactively offer the role to internal candidate and not let it happen by random internal employee raising their hand.
I applied for Chief AI Officer in mid-sized company on the day when the job ad was published. Received invitation to first screening interview right away. A day before the scheduled call there came email from HR explaining that my interview has to be cancelled, because role was filled in internally. Now, seriously, how do you accidentally find in 70 FTEs company good Chief AI Officer that you were not aware of?
The overlooked downside of the internal candidate preference is that too many open roles end-up never filled with external candidates, but still effort of 100+ candidates is wasted on studying the role description, applying, even going through several rounds of interviews. When you sit on candidate side of the table, this piles up in tens of pointless applications, all just because somebody want to (secretly) make their life easier. Can we have major rethinking here, dear HR teams?
PART | 9 | YOU LEARN things over time …
“Repetition is the mother of Wisdom” saying goes. But in hiring cycles you learn weird things.
Many experts are willing to enter job recruitment process when still in active role with argument that one should “sharpen the saw” or undergo some hiring cycles as a form of the drills. After you better, if you are to fail interview you better fail one you didn’t dream of first place. Thus, one would really expect that going through 432 interview opportunities you learn many things.
And you do indeed. But given the way that Tech hiring process is set-up now, learnings are split between things you are guaranteed to learn and things that are optional (do not happen to all of us). And the guaranteed learnings are not that rosy.
Bypassing mishaps. As mentioned in yesterday’s #8 sequel, companies try to illegally limit candidates by their geographies. So first thing you learn is how to swim around those illegitimate filtering’s.
How to type a lot. I can’t wrap my head around how stupid the companies are when it comes to application forms. The worst evil are companies who expect candidates to manually retype all experience and education records. Now maybe not issue for junior position, but honestly in mid-career after 7+ jobs and 3+ education completions, you have really this monkey feeling. If this happened to me several times a day, I simply skipped the next ones. If you think you can send Ai to fill-it on your behalf, only half true. To exactly prevent bots filing applications, forms are intentionally JavaScript heavy, loading fields dynamically or offering drop downs with values that might not be directly machine readable. Captcha being often part of the journey.
How to spell your LinkedIn URL However, the most ridiculous issue (present roughly 70% !! times) is even for Job Ads that you react to directly from LinkedIn to have to fill LinkedIn URL. How the HR teams probably don’t realize but to keep up with rapid fire of new applications appearing (and often taken down for enormous demand in 1-2 days later already), PEOPLE APPLY FROM MOBILES. Now, if you hit apply directly in the LinkedIn app, you can’t go grab your LinkedIn URL, if you try open it in browser, it will deep link you back into app. So you literally have to type https://www.linkedin.com/in/yourhandle If you were not clever enough to choose your real name for handle (I was lucky to grab /vitekfilip and you have just set of the number or gibberish letters, you gonna hate yourself (and still memorize that sequence). And it would only take hiring company very little effort to grab this directly from LinkedIn (e.g. Easy Apply button).
To move from cynical things into something real, you learn to read the expectations of the companies. When applying on LinkedIn, there are often follow-up (filtering) questions on years of experience with certain topics. (e.g. “For how long have you experience with managing teams?”) Sometimes they mention explicit threshold, but often not and hiring team has some secret cut-off level in mind and if you follow below their expected value, you will be automatically rejected. But rather than gaming this (they will find out later anyway, so don’t lie on those), it gives you extra signal about what they are looking for. For example if they ask about 7+ years of leadership experience and 2+ years of some expert topic, that gives you hint both for salary negotiations (mid senior pay level), but also on role positioning (we look for manager, who can be technical but is still primary manager).
It also gives you calibration. Both for length of the hiring process and for pay level on given market. For example, I was informed on second HR screening call that there will be 8 more rounds, out of which 6 will be my potential boss participating. I told them it would not happen with me. I don’t aspire to succeed in such requitement where my potential boss needs to see me 6 times before (s)he can decide to work with me. I exited the process. Because that was off the normal.
PART | 8 | LOCATION in Tech Jobs and Stereotypes ?
There are several aspects in which job markets got out-of sync over time. LOCATION is deadliest of those.
Historically, most of the work was physical or bounded to physical location (e.g. office). This got so strongly entrenched into HR and hiring managers that before COVID-19 vast majority of the roles have been On-site. Few remote roles did exist even back then, but Hybrid category did not exist anymore.
Of course corona lock-downs have shuffled this entirely, forcing us to over-expose to remote model. After we crawled out of pandemic years, several “Schools of Thought” emerged on this topic. Few employers realized that is reasonable quality of work can be done remotely, they save enormously on office rent, supplies and electricity. So they turned into remote-first companies. Most of the start-ups do not have (spare) funds for office rental, so they became remote-first by design.
Employees of course cherished the option to save commuting time and have remote work flexibility (e.g. working from multiple locations or workations model). So the preference stayed on Hybrid or Remote.
And then there is group of managers who do not trust in remote work and require people to be physically coming back to (office) location. But how does that translate into job market total mix?
Scanning the German Tech market in H2 2025 only 29% of the job postings declared Remote as working model. These are heavily start-up loaded, incumbent companies almost never appear here. Only mid-size companies from obscure locations realize that chances to find somebody locally are bleak, so they embrace the Remote as last resort. Due to strong push-back of candidates, 52% of German tech roles indicate Hybrid as acceptable model (citing 2O+3H or 3O+2H weekly schemas). But full 19% (so every 1 in 5) tech roles still require explicit On-site presence. But that’s still not the full truth of it.
Many companies require your postal address as mandatory application field. Only to reject non-local candidates even 52% of the Hybrid-preferrable postings. How do I know? Well after receiving an instant rejection within minutes for a role about 65 kms from my home, I could not help myself and replied again with “mistaken” PLZ (postal code), now receiving invitation to screening call.
In tech location is just a mental block that hiring people have. As EU citizen you can work in any EU country freely without any visa or work permit. They even do not have the right to reject you based on geography, if you commit to office policy. But both candidates and HR teams are standing here in their own ways. I once was in discussion with interesting company from Goteborg, Sweden. They requested 2-days in office presence and were offering very generous compensation packaged. I told them I am happy to come for 2 days a week. They could not wrap their head around this: “But you say you live in Berlin, Germany?!” Yes, and I checked there are 6 flights a day between Berlin and Goteborg, with tickets averaging 100EUR. Me taking the Swedish salary AND covering the travel costs I would be still better off. They literally hanged on me during the call. as not to be “ridiculous”.
And the learning lesson: Increase your pipeline with adding additional filter for all EU countries + remote roles. If you are brave (and ready to travel) you can add even the Hybrid ones for neighboring countries. But stop being your own enemy falling for Geo location. It’s just prejudiced stereotype.
PART | 7 | HOW MANY CV’s should you have ?
If you follow our series of Wicked Hiring Advent Calendar than you know that in first sequels of the series we introduced the errors and obsolete habits of the Tech hiring market. But this series is not to groan (or succumb) to the inefficiencies of labor market. This series aims to provide also the “so what “ part of the answer.
After explaining how many frogs should you kiss before you get your (job) prince yesterday, today we move into how to increase your top of the hiring funnel. In part #2 of our series we explained that candidate needs to apply to about 5-7 new opportunities per day to keep the interview flow continuously flowing (until you hit final success). This might get some of you panicked, because what if my role does not have 7 relevant offers opened per day ?
Given the pyramid of organizations, for individual contributors / freelancers role this is probably not the issue. When geographically broad enough thinking (which we touch upon tomorrow) almost for any individual role there are tens of new postings each day. However, for managerial positions this might not be true even if you extend your geo range to whole continent. So what to do about that?
The key to unlocking more options for you is to have several CV’s. Now, you might think “Hey, there is only one truth so how can you have multiple genuine, not lying or pretending CV’s in parallel?
This is the biggest mental block that candidates have: If I have been Head of BI, I should have CV outlining Business Analytics/Intelligence. And you definitely should. But if you happen to be Head of BI for Ecommerce, you also analyzed Marketing channels conversion data, User browsing patterns or Supply chain replenishment. Thus, besides generic Head of BI roles, you can equally try your luck with Marketing Analytics Lead or SCM Analytics Expert. The issue is that you should not do this with single CV.
The issue is that you most likely possess skills and experience that not only meet the requirements of particular of those 3 roles, but you also have skills irrelevant to that specific role. If you enlist all your skills on single CV you drown the hiring side into too much noise to pick the essential strength. Also you worked on projects worthy for all 3 roles, but you can’t sell all 3 in consistent single pager that recruiter will read about you. Therefore, be strategic about it:
* Sit down and outline what kind of different roles you should apply to. If your imagination is limiting you, throw your name-and-contact-stripped CV into LLM chat and ask for what other roles you would be credible candidate for.
* After obtaining list of roles, iterate for each role on list to read several job postings for given role. Look for overarching skills, project history or know-how that employers seek for each of the role. Again, when in doubt throw them into AI and ask to extract the common points for you.
* Then create clone of your master CV to highlight skills and role relevant past experience, achieving at (slightly) unique CV for each of the roles. (My advice make them also visually different so that you can easily tell one from the other, you will need to send each to different roles. Having visual clue helps not to mess it up. For illustration, my final role-specific CV’s looked following:

Store them all in your mobile (so that you can attach them to job respective offers equally easy. You will be surprised how hot of the candidate you are for “secondary” roles as well.
Punchline: Don’t try to hit all job openings with one-size-fits-all CV, you do yourself injustice. Create CV clones to highlight specific projects or skills for each type of the role, to boost roles you are comfortably eligible for.
PART | 6 | How it feels to REJECT GOOD JOB OFFER
Choosing right hobby, flat, life partner or new job is difficult. Not only because you need to find a good match for you, but also because you need to turn down good (yet not optimal) offer. But there is mathematical proof for optimal decision making preventing regrettably poor choice. Let me walk you through it:
Issue with us picking partners, houses or job is that set of potential options is too big to even get to know all theoretical options. Not every role is free when you are, same as not every house is on sale when you are on look-out for yours. As a result, we can assess only options that presented themselves (or we got to learn about hiddenly). But no one can meet all people of planet to choose life partner or to see all houses or employers in town. So how to pick best if you even don’t know if there are maybe better options?
Believe it or not there is algorithm designed for that bears mathematical proof of optimal choice. In expert literature this is named “Optimal Stopping criteria” but in regular population this is labeled “Secretary Choice Algorithm” (stemming from hiring for role of office secretary). You can read on this in book “Algorithms To Live By” (which I reviewed here).This optimal algorithm divides process into Scanning and Closing parts. But before you start you need to state yourself how many options do you have time (or other resources) to see at most. For example, if you unemployment benefits last 6M then you probably can only look for those 6M (of course, you can choose to invest some of your saving to go beyond whatever you are entitled to from social support or severance package.) Rather than time, you are better off counting pieces of job interviews you are willing to take, but that’s nuance.
So, if you know what your time/effort budget (let’s say you can imagine going through 50 interviews at max), then you divide this into 37% scanning and 63% closing. That means that in the first 19 cases = (37% * 50 ) you just take part, but don’t accept any of those no matter how good they seem to be. But you evaluate each option (in retrospect) and at the end of this scanning phase pick the best you have seen in these 37% scanning cases (Let’s say it was the 12th case) as benchmark.
Then you enter closing phase where you are gonna finally pick your choice. This should be the first option that you meet in closing phase that is better than best scanning option (12th case in our example). This way you are guaranteed to minimize regret and make good choice even if you at start didn’t know anything about market you are choosing from.
Now, if you have detailed knowledge of the market, you can choose to adjust the rule for you (e.g. shorter scanning). Or if there are objective criteria (e.g. Miss Universe meets you on 3rd date), you can do exception.
But the real power of this algorithm is to dare to refuse good looking offer (that is still not optimal). This happened to me as well. I was presented by very generous offer by Tim Ossenfort and his team. I had to turn it down. It was a bit awkward feeling (and there were times I felt like regretting it). I was great candidate, it took 8 stages to get to offer, and many would kill for that opportunity. Still, there were aspects that didn’t make it to Miss Universe (exception). Tim was truly outstanding leader to accept, didn’t get sour and we exchange text or two occasionally to stay in touch. And me? I found yet even better option later down the road. It was roughly 74/100 option for me, so it took lengthy and nerving months after NO to Tim and his team.
Punchline: When seeking new job, be ready to say now in early scanning phase ( ~ 37% of planned search time/cases). Once beyond scanning point take first option that is better than highest benchmark seen in scanning. This optimizes for best choice. Though you might feel down about turning down some really good (looking) choices.
PART | 5 | How I nearly fell into Labor Exploitation scheme
You likely heard of pyramid financial games or shady multi-level-marketing (MLM) schemas. Experts coined “Ponzi scheme” name to label these practices. They create (fractal-like) hierarchy and exploit individual financial contributions of lower ranks (sent to top of pyramid) who are lured with vision of them becoming top of their own sub-pyramids. Now, would you believe there are Ponzi schemes exploiting labor as well?
If you entered our Wicked Hiring Advent Calendar today, let me just briefly outline that this is 5th episode of our series on How broken the Tech Hiring market is. While in first 4 sequels we discussed apparent process issues that stem from negligence or clinging on outdated principles, today we enter more bizarre waters. As there are also nefarious and ridiculous actors on market that should not be there first place. Let me share with you experience of me coming across some in my experiment. (I entered into 432 job search processes to test how exactly Tech hiring works).
It all started with solid job ad on LinkedIn. It promoted managerial role to lead mid-size team of data, analysis and IT automation specialist. After studying the role and confirming my profile should resonate with offer, I attached my CV and hit “apply”. In about 2 days I received LinkedIn message with positive answer and invite to schedule a first call with SMS/Whatsapp in desired time. So far nothing of unusual, this is relatively common practice from headhunters.
After sending few proposed time slots, there was a silence for few hours only to receive WhatsApp from Barbara at 18:30 with request “Can we call NOW?” Well, unsocial talking hours are never green points on potential employer resume, especially if applied this abruptly and ignoring suggestions I was asked to give. As we were in middle of family dinner, I replied “I can’t talk, but will be available in about 30 min when I plan to walk the dog.”
The other side replied with “No worries, I will explain in the chat, and we can talk afterwards.” And then I received set of messages explaining that employment is:
- Fully remote
- At first I’ll work hands-on myself. The team they talked about, I will have to gradually recruit myself
- You start with 6 weeks training, where each week you will be mentored by existing team manager on skills (like video editing, website building, performance marketing set-up, etc.) and have to pass certification exam + complete tasks of given type for each week.
- No fixed salary, all variable (now that’s not even legal in most EU countries). You are directly paid for any work you do.
- This is all “work+learning+grow” and it’s combined with kind of “gamification”
This was already quite diversion both from what I wanted to do but also from what job ad was luring in. So being in chat mode, I asked: Who actually decides how much work I get? Barbara replied that first I’ll join her group and when I can recruit (and onboard) my own team members I will be getting the tasks directly from “central pile”. Who creates central pile I never learned. But I was assured that “you start with easy tasks and work yourself to more sophisticated”
The scheme was getting clear and “naked: in my eyes, so I pressed for one more information: How is one renumerated? “First 6 weeks you learn and you work on tasks proving your competence. So no pay. After 6 weeks you can get 15-20 different tasks a week (!) averaging 35-100 EURs each. So if you work hard, you can each about 1200 eur/week brutto. But your income significantly increases when you recruit your team, because you receive share of pay for tasks they complete.”
At this point, I heard all I needed. You invest 6 weeks of work without a pay, then you are pushed to do low-level tasks at mass only to recover your “invested training time” and you are expected to recruit more people for this hamster wheel for them to work for you the same way. All for about ceiling of 5K EUR pre-tax income per month, no guarantees attached.
Moreover, this “irrefusable” offer came with no official company name given, was expected to pay your “salary” over PayPal (!) and no mustrum of contract was immediately available. It was easy “No, thank you, not me”. But it struck me that there are in 21st century real labor exploitation schemes that dare to advertise (and scout) even publicly on LinkedIn.
So be aware!
PART | 4 | Most TOP MANAGEMENTS terribly MISUNDERSTAND AI
Current state of AI hiring: Existing company managers have (mostly) no AI experience, but they hope to keep their well-paid jobs by hiring AI experts under their command (to implement AI).
In first sequels of our Wicked Hiring Advent Calendar we spent time discussing the calamities of (Tech) hiring habits and processes that are visible from the outside. However, obscurity of AI hiring has also one strong intrinsic hurdle: There is complete and utter misunderstanding of How AI progress can be achieved.
As a result, many think about AI as “technology to implement”. Almost like on-premise to cloud transformation or paperwork digitalization from past. This is, of course, terribly wrong. Because those who really can build AI agents are already building them on their own and selling them as products. They don’t need (and neither dream of) joining some corporate ranks to bag for resources or fight high-politics-stakes battles. As a result, these incumbent managers end up with contracting advisors/consultants or hiring individual contributors, who know particular (party-trick) use-case that company overheard on Tech conference catering others (boasted to) had implemented. Few quarters down the road you end up with isolated islands of mini automations.
Nobody pauses to realize that if AI will be as transformational as they polish/pronounce it to be, it would probably warrant CEO or somebody on board level to be AI-deeply-literate. Or even worse, board members assume some of them will (gradually) turn into AI experts themselves. So what’s the fuss?!
The most common follow-up scenario of this misunderstanding is for CTO’s to end-up to be the “best fit” for AI challenge. Some of existing CTOs even proactively sway themselves into matter. Yet another companies seek to onboard external “CTO with AI experience”. But here reaches the AI misunderstanding its utter peak. Follow the thought with me, please: If you were leading Machine Learning or AI teams so-far, you have been Head of Data Science, Chief Data or Chief AI Officer. But not leading other SW engineers, System architects or Sys admins. If you have been practicing CTO, you have worked on Infra, CI/CD, Front-end and Back-end development, but not overseeing Computer Vision, Embeddings or NLP, and most of “your” developers never wrote single line of Python or Spark. “CTO with AI experience” is (almost) empty Venn-diagram overlap. So asking for CTO with AI track record is either forcing CDO to grow extra non-AI tech leadership arm, or CTO to sugar-coat their AI capabilities. Which one would you (rather) bet on?
But C-suites still don’t get (or chose to not get it). They throw out job offer for AI transformation leader only to test candidates on coding from Java, node.js or PHP. Only to interview about Agile or CI/CD principles, scrutinizing how to hire quickly Senior front end developers.
So let me put me straight to your face: “Dear C-level managers, if you do not have on highest level anybody who developed AI him/herself, you better get one and damn invite them to join you in your closed circle. You can’t out-hire yourself out of recent AI absence by employing AI individual contributors somewhere down in lower ranks. And if you keep fooling yourself that “AI needs to be implemented”, you will parish in dramatic shake-up after your competitors leave you 10x behind in speed of progress. By the way a bit of the hiring hint: How do you tell real AI top-manager from CTO aspiring to be one? If thought-through concept of building AI-only SW development process was not even hinted by candidate, you better pass on. You are not talking to AI-aware leader, so why waste both sides time. But first of all, stop fooling yourself AI is yet another technology to implement.
Punchline: Top managements want to run company as before, just to infuse AI in “layers below”. Real AI plan does not assume (or ask) human FTEs or vendor budgets. CTO with AI experience is misnomer.
PART | 3 | Time to answer? NO’s come 2 days earlier than Yes’es
Job offers arise continuously every day, even literally every hour. Habit of publishing the new positions in unsocial hours is really strange phenomenon worthy separate sequel of this Wicked Hiring series. (Because companies publishing new job offers in the middle of the night actually favor bots (that are ready to react any time) over humans. Thus, if late-night-owl recruiter posts new job at midnight last thing before going to bed), (s)he wakes up with only to be surprised to find 100+ profiles already reacted. Almost none of that are genuine human initiatives. So make your call.
One would foolishly assume that continuous inflow of the fresh job ads signals continuous work with the candidates as well. But anybody who has been looking for job lately can confirm for you “Those were the times …”.
We already touched in PART #2 of series upon the fact that more than half of the offers you send as candidate will be fully ghosted (no reply at all, not a single word back). But if you hoped that the other (almost) half are the good ones, well, sorry to crash your dreams.
Only about 10% of the recruiters reply within 48 hours of your application. Yes, 1 out of 10 in first 2 days. If you apply to LinkedIn job posts directly, there seems to be (automatic) SLA for negative replies for 3rd working day, because surprisingly a lot “No thank you” come exactly on 3rd day. And then, it is just long tail. Worst 10% of replies take more than 3 weeks for first contact (!). Honestly, those are probably not very promising by itself, but be my guest to give them benefit of doubt. If you exclude the automatic NO’s , median time for the first touch (proven by data) is about 5 calendar days. This is aftermath of human recruiters working in batches. Unless pushed by top management for some urgent role, it makes sense for them to review inflow of CVs in batches every x-days. For that phenomenon, hiring resembles more like seeing the doctor: Most time of your trip you spend waiting in the fore-room.
Now this is not only enough for you to bite down your nails, but also has severe implications for the rapid fire of applications you need to achieve to keep the progress somehow working for you. Because if you want to have job interview at least 2-3 times a week, compounding the ghost-rate and usual response time, you need to have continuously open 35-40 different job openings. Now stop for a while and read the previous sentence again!
Yes, job market is so broken that when you send less than 35 CV’s a week, you are unlikely to have any hiring interview scheduled for next 5 working days. They will convert in some form into talks maybe later, but that’s the Tech hiring number game now. That means to keep your pipeline hot, you need to react to 5-7 new offers per day! If you panic that “There are not 35 new positions a week opened in my location for me relevant roles” , you are probably right. But there is some remedy to that. And I share the hacks in our Wicked Hiring series in next days soon.
Punchline: Expect about 5 days for “positive” answers to come on average. Quick Nos usually arrive in 3 days. That also mean you have Nos earlier than MAYBE’s. So get mentally ready for dirt (and crashed feelings) paves the road to progress.
PART | 2 | Searching Job Is Riskier Than Lottery
One looks much calmy and with understanding on job market, if (s)he had chance to swim the river from other embankment as well. As seasoned hiring manager, I had the privilege of hiring 90+ people into Tech roles in my career so far. Therefore, I know hiring has been always numbers game. But for both sides.
For ages the candidate side of the game was running 10:3:1 rule. Out of 10 (well addressed) job applications, you would here back from 3 and you should turn at least every third CV screening call into next round progress. Well that one is definitely gone.
To make this proper experiment, I decided to store every single communication about the job opportunities I entered. As my focus was generously broad (from Global remote roles all the way to on-site job in Germany, where I stay), I used common LinkedIn platform to make the job discussions somewhat standardized and comparable.
Over the last 6M I opened the discussion with 432 roles in 373 companies. Yes, you are reading right, 400+ processes. I meticulously kept timestamps of each interaction with each of the opportunity. When did I receive first reply, what was next step, how much down the road I got? How many rounds were there for each of the role search (indicated)? Having this detailed data allows me to draw clear conclusions.
In hiring (for tech roles) we are recently in ghosting era. Why so? Well, out mentioned 400+ roles, I never received any answer (not even “After careful consideration …”) in 52% of the cases. Let me repeat it again. You apply for the job that your skills match and in more than half of the cases you don’t receive even automatic reply. Zero interaction, nothing.
If you are one of those, who’s self-confidence is not cracking stones into pieces, you most likely slide into depression. What is wrong (with me)? – ask many candidates themselves. If you belong among “challenge accepted” hardy individuals, you adjust the game. Because all of the sudden the rule changes into 65:5:1. So to get to talk to at least 1 promising hiring manager talk, be ready to send out as many as 65 applications.
Job hunting is not about chances; after all, it’s not a lottery. It’s worse than that. Because most of the national-wide lotteries have at least 4.2% (some of them as high as 11%) chances. Thus, every 1 in 24 cases wins at least something back. With Job applications you are getting first talk with hiring manager in 1 to xx cases. This is nuts. Because we still call participating in lottery hazardous behavior. So now looking for a job is even more risky than lottery participation?
Seeing this, you surely ask: “What happened? Why all the sudden? Well, having the detailed data on all cases helps me not only spotlight this problem, but also point out the actual causes of this phenomenon. We will invest into each of those root causes separate sequel of this Wicked Advent Calendar. But just to tease you a bit, they include Slavery of internal offers, Absence of dating math (this will be extra fun to read), AI cynism, Wrong level of hiring manager and Economics masquerade.
Punchline: Forget 10:3:1 rule, get mentally ready for 65:5:1 rule. Don’t try to fight it, it’s not your fault, it’s new (de)fault.
PART | 1 | WHY Job Market is BADLY broken
We often do not believe how broken things are, before we experience them ourselves. So was the case of the Labor market for (AI roles). Looking for job was (with exception of few booming years) never easy. Specially some industries and roles might have challenging to find new job opportunity. Therefore, I get friendly shoulder taps when …
… when I say I am/was looking for the AI job. “That’s so hot, there must be huge demand, and you certainly have plethora options to choose from.” Well, honestly, that’s what was my piece of mind when I had decided to take some break from previous role. But over the time, I learned that job market is really badly broken.
No matter that you hone top-notch AI skills, you have track record in the most booming industry, you can pass live coding challenges or have strong reputation or network, you will be exposed to same abyss of bizarre experience. Completely orthogonal to your skills or ambitions, as it’s all HR habits and processes that are out of sync with time and reality, to say the least. Over the course of 6 months, I came across labor scams (yes!), candidates ghosting, shields of application forms, empty hands (and promises) of head-hunters, crude misunderstanding of AI , free labor illusion and hiring practices from 90’s. All stemming from 400+ job processes I personally went through.
As I didn’t want to drop these things just into my own well-of-disbelief , I decided to release it as Wicked Hiring Advent Calendar. Over the next December days I will regularly release the daily portion of what actual labor market (for AI positions) looks like. And unbelievable stories can I promise. So stay tuned to summarizing blog or regular LinkedIn posts
 🤔 Why “
🤔 Why “ If you ever went through some Strategic management training, this name might ring the bell with you. You also might roll your eyes, as Renée Mauborgne and W. Chan Kim published their first introduction to Blue Ocean in 2004, so whooping 20 years ago. But wait I am not that ignorant, there is more to this suggestion.
If you ever went through some Strategic management training, this name might ring the bell with you. You also might roll your eyes, as Renée Mauborgne and W. Chan Kim published their first introduction to Blue Ocean in 2004, so whooping 20 years ago. But wait I am not that ignorant, there is more to this suggestion. Many authors and books try to explain the major shift in
Many authors and books try to explain the major shift in  Decision to put this book on my reading list was stemming from the curiosity. The book reviews suggest that this book is good entry-book for executive trying to be data-driven or AI-ready. Being SVP Data & Analytics (and seasoned Data Scientist) myself, hardly the fit for my career phase. But I have seen so many books claim (and fail) to introduce you to Data Science bushes, that I was tempted on how this book will be doing? Yet another flat-falling promise?
Decision to put this book on my reading list was stemming from the curiosity. The book reviews suggest that this book is good entry-book for executive trying to be data-driven or AI-ready. Being SVP Data & Analytics (and seasoned Data Scientist) myself, hardly the fit for my career phase. But I have seen so many books claim (and fail) to introduce you to Data Science bushes, that I was tempted on how this book will be doing? Yet another flat-falling promise? As somebody shaping (literally) thousands of visualization year after year, I welcome books describing the rules and good (and bad) practices for creating visualizations. I have few in my library (and suggested them in my previous reading lists), but they often talk more about what kind of graph to chose and how to shape the composition. Many of them take use of color for granted (or touch the issue only from the side).
As somebody shaping (literally) thousands of visualization year after year, I welcome books describing the rules and good (and bad) practices for creating visualizations. I have few in my library (and suggested them in my previous reading lists), but they often talk more about what kind of graph to chose and how to shape the composition. Many of them take use of color for granted (or touch the issue only from the side). Many admire
Many admire  I have read most of 15 books that @DavenportTom authored and mostly were happy about them. Therefore, when I saw his newest piece ALL IN ON AI, I was full in anticipation.
I have read most of 15 books that @DavenportTom authored and mostly were happy about them. Therefore, when I saw his newest piece ALL IN ON AI, I was full in anticipation. Reading Sam Gilbert’s book Good Data is stimulating and entertaining at the same time (you just need to see through authors masked humor). Sam is seasoned data professional, who does not fall into cliche and mental short-cuts oof today’s data speak.
Reading Sam Gilbert’s book Good Data is stimulating and entertaining at the same time (you just need to see through authors masked humor). Sam is seasoned data professional, who does not fall into cliche and mental short-cuts oof today’s data speak. Web and App’s became our window of everyday activities, social interaction, shopping and most of of work (certainly so during COVID). In 1990’s and 2000’s institutions and businesses were trying to impress us by physical real estate. But how do us digital institutions treat now?
Web and App’s became our window of everyday activities, social interaction, shopping and most of of work (certainly so during COVID). In 1990’s and 2000’s institutions and businesses were trying to impress us by physical real estate. But how do us digital institutions treat now? At first glance, the subject of online influencers might not seem like a page-turner. However, a friend’s recommendation led me to Taylor’s exploration of the hidden layers behind social media’s evolution, and I was instantly captivated.
At first glance, the subject of online influencers might not seem like a page-turner. However, a friend’s recommendation led me to Taylor’s exploration of the hidden layers behind social media’s evolution, and I was instantly captivated. This book feels like the Swiss Army knife for machine learning enthusiasts. It’s the first of its kind as it dives into the wild world of ML design patterns. Forget about dry, technical jargon; this book is like a treasure map, guiding you through 30 quirky, yet ingenious design patterns, each one a secret weapon against those head-scratching ML problems. It’s like finding cheat codes for a video game, but for machine learning!
This book feels like the Swiss Army knife for machine learning enthusiasts. It’s the first of its kind as it dives into the wild world of ML design patterns. Forget about dry, technical jargon; this book is like a treasure map, guiding you through 30 quirky, yet ingenious design patterns, each one a secret weapon against those head-scratching ML problems. It’s like finding cheat codes for a video game, but for machine learning! As someone with a background in Strategic Management, I’ve devoured nearly every strategy book available. Through my extensive reading, I’ve discovered two authors who consistently deliver valuable strategic insights: #GaryHammel and #RichardRumelt.
As someone with a background in Strategic Management, I’ve devoured nearly every strategy book available. Through my extensive reading, I’ve discovered two authors who consistently deliver valuable strategic insights: #GaryHammel and #RichardRumelt. The Choice Factory” by Richard Shotton is an exceptional read, especially recommended for data analysts focused on human behavior modeling and prediction, as well as marketers seeking to boost their marketing conversions via leverage (or taking tail-wind of) natural human tendencies.
The Choice Factory” by Richard Shotton is an exceptional read, especially recommended for data analysts focused on human behavior modeling and prediction, as well as marketers seeking to boost their marketing conversions via leverage (or taking tail-wind of) natural human tendencies. The Ruthless Elimination of Hurry,” as the title aptly indicates, is more than just a book; it’s a compelling manifesto advocating for a deliberate shift away from the relentless pursuit of speed for its own sake.
The Ruthless Elimination of Hurry,” as the title aptly indicates, is more than just a book; it’s a compelling manifesto advocating for a deliberate shift away from the relentless pursuit of speed for its own sake. Ah, the wild ride of prototyping machine learning models! Many of us have gone through fast prototyping (or toy examples) of the Machine learning clustering or prediction models in notebooks or sand-box environments. It’s like building a Lego castle in your living room – fun, easy, and oh-so-satisfying. But then, you decide to move that castle to the real world, and suddenly, it’s like trying to assemble it in a windstorm. Surprise! Porting your perfect little prototype into the jungle of a live environment is like herding cats while juggling.
Ah, the wild ride of prototyping machine learning models! Many of us have gone through fast prototyping (or toy examples) of the Machine learning clustering or prediction models in notebooks or sand-box environments. It’s like building a Lego castle in your living room – fun, easy, and oh-so-satisfying. But then, you decide to move that castle to the real world, and suddenly, it’s like trying to assemble it in a windstorm. Surprise! Porting your perfect little prototype into the jungle of a live environment is like herding cats while juggling. As the title of the book rightly suggests, text has been for long perceived as special “animal”. On the edge of the data analytics, much more obscure than analysis of the relational data by SQL or by Predictive analytics. Text analytics was also managed by dedicated (python) packages and often by NLP-specializing-only staff. If you were not one, you would probably just reach out for (simplified) predefined functions in NLTK (or similar code library).
As the title of the book rightly suggests, text has been for long perceived as special “animal”. On the edge of the data analytics, much more obscure than analysis of the relational data by SQL or by Predictive analytics. Text analytics was also managed by dedicated (python) packages and often by NLP-specializing-only staff. If you were not one, you would probably just reach out for (simplified) predefined functions in NLTK (or similar code library). Hold onto your hats, folks! Mustafa Suleyman’s “The Coming Wave” isn’t just a book; it’s like a roller coaster ride into the future, where your coffee maker might be plotting world domination. Suleiman, the AI whiz-kid and DeepMind co-founder, is dishing out a buffet of mind-boggling predictions. Imagine a world where your vacuum cleaner is judging your music taste and your fridge is gossiping about your late-night snack habits. That’s the kind of AI party Suleiman’s inviting us to.
Hold onto your hats, folks! Mustafa Suleyman’s “The Coming Wave” isn’t just a book; it’s like a roller coaster ride into the future, where your coffee maker might be plotting world domination. Suleiman, the AI whiz-kid and DeepMind co-founder, is dishing out a buffet of mind-boggling predictions. Imagine a world where your vacuum cleaner is judging your music taste and your fridge is gossiping about your late-night snack habits. That’s the kind of AI party Suleiman’s inviting us to. No, this is not a mesh of the Shakespeare’s famous love novel and Performance marketing guide. Julia might still be the new kid on the block in the programming world, especially compared to Python, the reigning “lingua franca” of data science. But don’t be fooled – this emerging language packs a punch with its speed and efficiency. “Julia High Performance” by Avik Sengupta and Alan Edelman is like the ultimate guidebook for this speedster of a language.
No, this is not a mesh of the Shakespeare’s famous love novel and Performance marketing guide. Julia might still be the new kid on the block in the programming world, especially compared to Python, the reigning “lingua franca” of data science. But don’t be fooled – this emerging language packs a punch with its speed and efficiency. “Julia High Performance” by Avik Sengupta and Alan Edelman is like the ultimate guidebook for this speedster of a language.