They are Cinderellas. Most people look at them with disdain. They combine slightly lower comfort with more effort. And this is, let’s face it, not exactly the most lucrative combination you can think of. However, they are more spatially concise and thus more practical as well. And if you add electricity to them, that’s already another level.
Have you guessed what the previous mysterious paragraph referred to? Yes, we’re talking about scooters, my favorite vehicle. Berlin is a city strongly inclined to cycle traffic. Over 500,000 people are estimated to travel here every morning on various forms of (human-powered) wheels . Yes, you read correctly: 500,000 people every morning. Berlin hosts incredible 620 km of cycle paths or sidewalks built within the city. What is more, in Berlin, as in one of the few cities around the world, bicycles can even be taken to the subway. Simply a cycling paradise on Earth.
Scooter metamorphosis
But back to scooters: Two years back, when I started riding my scooter around streets of Berlin, I met with general amazement and sarcasm. Some of the “real cyclists” have even mocked “if they didn’t have pedals in the bike shop when I was there.” (the fact that the funny cyclist with his pedals did not catch up with me ever after that day, I leave aside for now). However, the situation around scooters has changed significantly over the last 18 months. Electric scooters entered the game.
The austerely designed scooters, equipped with an engine, can go over 20 km/h. Their main advantage is that you do not need a driver’s license to rent them, so they can be borrowed by anyone, whether you are a tourist or a local citizen. This is probably just one of the reasons why literally a “scooter war” is raging in the biggest German cities. According to independent estimates, more than 4800 electric scooters operate in Berlin alone. To put it in context, there are approximately 4,000 streets in Berlin, so there is already more than one electric scooter per each street street today. The purpose of this blog, though, is not to delve into the comparison of market shares or the quality bench-marking of individual services; (this is done well here) Electric scooters conceal one more interesting surprise.
The combination of their considerable number and the fact that each scooter is equipped with a number of sensors create a very interesting data sets for many (not just scooter operation relevant) Data Science analyses. This, at first sight inconspicuous, corner of data analytics even made it last month to its own topic of AI Meetup, here in Berlin. Hence, I can give you first hand report on what you can actually analyze around scooters.
When and where to place them
I remember a little embarrassing start of bike-sharing application in my home town, where initially the problem was mainly that bicycles were not where they were in demand, and on the contrary, they parked abundantly in places nobody desired them to be. The main reason for such a disparity is fact that the flow of traffic in the city is not symmetrical. If a taxi driver takes you in the evening from the center to the suburbs, it would be naive for him/her to stay in the suburbs waiting (in order to maximize fuel efficiency) to drive someone in the opposite direction at night. Obviously (s)he would have to wait until morning when everyone was back in town. However, as time is money, it is better to take the car “at own expense” back to the center, where it easily gets another order. What we consider to be quite logical for taxis, for scooters, takes a completely different dimension. The scooter cannot (for the time being) move itself and therefore it is necessary (several times a day) to transport scooters between individual stations when operating such a sharing services. And here comes the first data science opportunity that needs to be resolved: “When and where should scooters be relocated so that the cost of relocating them is covered by additional revenue from the new location where you put them?”
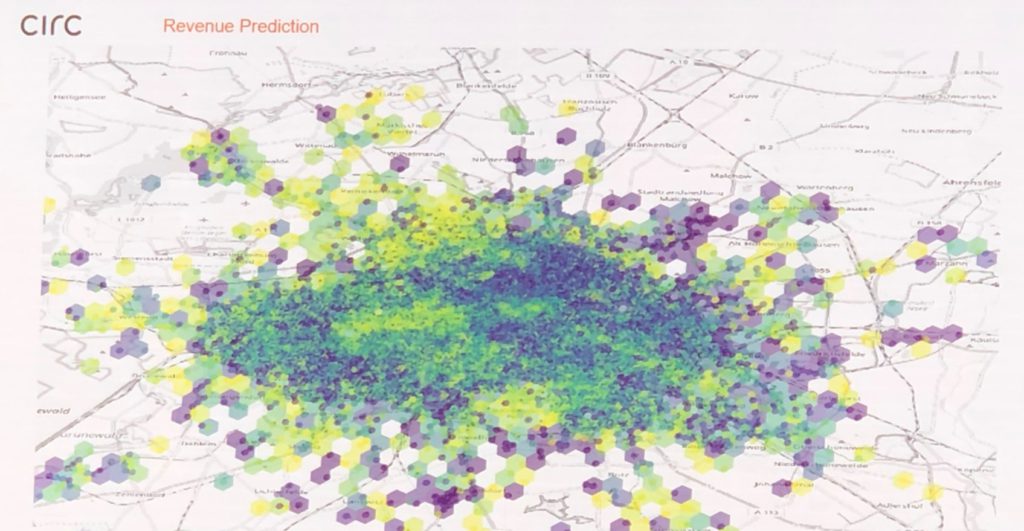
The figure above illustrates how one of the scooter services in Berlin took up this task. They have created a demand map based on their driving history data. However, demand is not in frequency measure, but directly in revenue value. A different shade of points indicates how much revenue a scooter (on average) achieves when starting from that very location. Therefore, it is necessary to pair up places with pale color with closely neighboring dark points. Add a radius that a person is willing to go to fetch a free scooter and you have a preliminary plan on how to move them. That it really works like that I saw one evening with my bare eyes: The delivery of the one of the companies stopped at a place where there were suspiciously too many scooters, the driver got off and put some of the scooters on the hull, ordering the other in line. And off he was to a better place for them.
New energy influx

Scooters need to be “visited” not only because of their location, but also because they are electric. If you rent a car, you are obliged to refuel it. However, you rent a scooter for a few minutes and you do not have a place to refuel it with electricity. (Although there are first attempts to motivate last-in-the-day users to take the scooter home and recharge it overnight.) In addition to relocation logistics, scooters’ batteries also need to be replaced. (Which is faster than recharging them on site.) Of course, it would be ideal if the scooter transfer could be combined with a battery change, but the battery would also run out of scooters that are in optimal locations or where there are enough other scooters, so one less charged piece can quietly wait there until the next visit of the charging patrol. How long routes do people usually make from the place where the scooter is parked? What is in reality a critically low battery state for that location? And what recharging the battery at this stage will mean for the overall battery life in the future? These are just some of the considerations that a data team planning to replace batteries needs to count into overall optimization decision.
User profiles and micro products
 As with any service provider, for scooters, the main goal is to get to know their users. Because if you do not want to bite you nails every morning, with worries if you earn enough today, you need to know the habits of your clients. Hence, a separate topic of Data Science help is client segmentation with assignment of expectations and commercial value for each of the segments. A person who rides your scooter to work has a totally different customer value than a tourist who has tried your service out of the curiosity. On the other hand, a regular user will be much less tolerant of a missing or damaged scooter near his home. And since competition is numerous, any disappointment of regular clients can easily lead to their loss. It is, thus, super important to properly design the micro products (weekly ticket, offer of the day, …) to keep the client loyal.
As with any service provider, for scooters, the main goal is to get to know their users. Because if you do not want to bite you nails every morning, with worries if you earn enough today, you need to know the habits of your clients. Hence, a separate topic of Data Science help is client segmentation with assignment of expectations and commercial value for each of the segments. A person who rides your scooter to work has a totally different customer value than a tourist who has tried your service out of the curiosity. On the other hand, a regular user will be much less tolerant of a missing or damaged scooter near his home. And since competition is numerous, any disappointment of regular clients can easily lead to their loss. It is, thus, super important to properly design the micro products (weekly ticket, offer of the day, …) to keep the client loyal.
When to see the doctor
Like any thing that does not have one owner, the biggest Achilles heel of shared scooters is that they have many users, but none of the scooter-caring “owner”. In addition, the scooters have mostly subtle (less than 12 inch) wheels that get tough times when the scooter is highly busy. Although the feedback from experienced defects gradually helps to boost the lifetime of individual scooter models (by adjusting their design), most of the current riding units will not live for more than 14 months; In really busy locations this value can fall as low as 10 months. Even though this may seem a complication especially for scooter companies at first glance, in real life it is more of an inconvenience for the end users. Imagine using a scooter to commute to work. You see on the map that some piece is available, so you can count on it on this mode of transport for your way to work . However, when you come to a scooter, you find that it is broken and you are left in limbo how to meet your first meeting starting time. Too bad. Now even discussing the scenario that your scooter damages within your ride, exposing you to real life-threatening moments.
 Therefore, one of the key topics of data analytics in this industry is fault prediction (technically called predictive maintenance). If historical failure data are correctly recorded, it is possible to see which factors of use increase or decrease the failure likelihood. At the same time, the company has complete information on what kind of usage are currently undamaged units subjected to, it can identify specific vehicles that are likely to break down in the coming days/hours. Since the individual scooters (as discussed above) need to be relocated regularly, the by next relocation schedule the actual malfunctioning can be prevented by replacing the soon-to-fail piece with a new one. This significantly reduces the risk of inconvenience to final clients and also prevents injuries. All this, though, requires one more interesting analysis, which we will turn to in the next paragraph.
Therefore, one of the key topics of data analytics in this industry is fault prediction (technically called predictive maintenance). If historical failure data are correctly recorded, it is possible to see which factors of use increase or decrease the failure likelihood. At the same time, the company has complete information on what kind of usage are currently undamaged units subjected to, it can identify specific vehicles that are likely to break down in the coming days/hours. Since the individual scooters (as discussed above) need to be relocated regularly, the by next relocation schedule the actual malfunctioning can be prevented by replacing the soon-to-fail piece with a new one. This significantly reduces the risk of inconvenience to final clients and also prevents injuries. All this, though, requires one more interesting analysis, which we will turn to in the next paragraph.
Quo vadis
 At first hearing, it seemed to me as an unnecessary academic exercise. But the more I had the chance to discuss it with the insiders, the more it made sense to me. Yes, we are talking about profiling roads ridden by scooters. As shocks are an unwelcome “pleasure” for both fine electronics and wheels, knowing how much time the scooter has traveled on which surface has been an important factor in predicting wear. Likewise, when did the scooter went downhill or up the hill, as it strains the physical parts of the scooter more than on the flat ride profile. Last but not least, it is important to know where the ride happened also due to cycling lanes coverage or risk of accidents in individual sections. Thus, the most advanced analytical teams extend map data with layers of data such as which streets have cobbles, what slope a given street has, or how many of our own service (and other road accidents, e.g. by cyclists) have taken place at each location. Initially, this data is likely to be used for internal scooter operation and technical improvement purposes mainly. However, later a different price per kilometer is also possible, depending on where exactly did the scooter drive through, to take into account wear (and indirectly motivate people to drive on more gentle surfaces.)
At first hearing, it seemed to me as an unnecessary academic exercise. But the more I had the chance to discuss it with the insiders, the more it made sense to me. Yes, we are talking about profiling roads ridden by scooters. As shocks are an unwelcome “pleasure” for both fine electronics and wheels, knowing how much time the scooter has traveled on which surface has been an important factor in predicting wear. Likewise, when did the scooter went downhill or up the hill, as it strains the physical parts of the scooter more than on the flat ride profile. Last but not least, it is important to know where the ride happened also due to cycling lanes coverage or risk of accidents in individual sections. Thus, the most advanced analytical teams extend map data with layers of data such as which streets have cobbles, what slope a given street has, or how many of our own service (and other road accidents, e.g. by cyclists) have taken place at each location. Initially, this data is likely to be used for internal scooter operation and technical improvement purposes mainly. However, later a different price per kilometer is also possible, depending on where exactly did the scooter drive through, to take into account wear (and indirectly motivate people to drive on more gentle surfaces.)
Try on your own, maybe …
If you are interested in scooter data, there are already several Open data sets that are freely available. So far not directly from Berlin, but apparently for start that does not matter that much. Thus, if this article have “got you started” to analyze scooter data, try one of the above tasks on the Open data sources on your own. Maybe you will be get attracted to work in one of the scooter companies. Or at least it pokes you to try some e-scooter service first place.
 But this rosy it looks only if you are the business owner. A less optimistic shade surfaces for you if you are a developer charged with task to program the very game. According to the data published at the conference
But this rosy it looks only if you are the business owner. A less optimistic shade surfaces for you if you are a developer charged with task to program the very game. According to the data published at the conference  And so the prisons came to focus as well. The Artificial Intelligence Instruction Program, developed by the University of Helsinki, has become an official re-qualification program for prisoners since May 2019 to improve their labor market chances after end of their sentence. Prison in Turku, south of Finland, has indeed purchased computers and tablets from a government grant and real AI lessons have been already launched in there. That it is not a pseudo (or pretended) attempt is confirmed by the fact that for AI course exercises the prison had to allow access (white-list) set of websites from which the course grabs needed data sets. Completion of the course ends with an official certificate for inmate. The University of Helsinki even committed to grant convicts credits for the passed courses, so that they can study the full science degree after being released from the prison. The program, running in Turku since May 2019, will be now extended to 3 more prisons in the country as of this month.
And so the prisons came to focus as well. The Artificial Intelligence Instruction Program, developed by the University of Helsinki, has become an official re-qualification program for prisoners since May 2019 to improve their labor market chances after end of their sentence. Prison in Turku, south of Finland, has indeed purchased computers and tablets from a government grant and real AI lessons have been already launched in there. That it is not a pseudo (or pretended) attempt is confirmed by the fact that for AI course exercises the prison had to allow access (white-list) set of websites from which the course grabs needed data sets. Completion of the course ends with an official certificate for inmate. The University of Helsinki even committed to grant convicts credits for the passed courses, so that they can study the full science degree after being released from the prison. The program, running in Turku since May 2019, will be now extended to 3 more prisons in the country as of this month. Some are more original and aggressive (like Finland), some countries are content only to copy the US, China or Japan. Slovakia is now also in this creation process and since I am honored to be part of it, here you can read
Some are more original and aggressive (like Finland), some countries are content only to copy the US, China or Japan. Slovakia is now also in this creation process and since I am honored to be part of it, here you can read 
 The invention of a gramophone (and soundtrack recording) had brought a fundamental revolution in music units. Music suddenly stopped being sold in experience units (which will have its historical implications, but we will revisit it later), but the the music medium has become the unit of music. Firstly (gramophone) vinyls, then magnetic tapes and CD’s ultimately. Since most of us were born already into this set-up, we don’t find it strange. However, when you get a little historic zoom-out, you may realize that selling music by a “medium unit” is like selling sausages by area of the packaging or health by number of blood cans. On other words, it is not important how much benefit you buy in the package, literally, only the size of the package matters.
The invention of a gramophone (and soundtrack recording) had brought a fundamental revolution in music units. Music suddenly stopped being sold in experience units (which will have its historical implications, but we will revisit it later), but the the music medium has become the unit of music. Firstly (gramophone) vinyls, then magnetic tapes and CD’s ultimately. Since most of us were born already into this set-up, we don’t find it strange. However, when you get a little historic zoom-out, you may realize that selling music by a “medium unit” is like selling sausages by area of the packaging or health by number of blood cans. On other words, it is not important how much benefit you buy in the package, literally, only the size of the package matters. The figurative last nail into Album’s coffin was an apple. In order to re-balance a reputation from the gravitational law (when fame was treacherously attributed entirely to Newton, and the apple got out of it with mere proverb “didn’t fall far from the tree.”) Taught by this crisis, this time the apple left nothing to chance and under its English pseudonym “Apple Inc.” brought the World the iTunes application. (which broke the album metric system for good). In Apple products, the music was suddenly available, God help us, by pieces. The world order has turned again from the head to its feet and you could buy (in the sense of the above analogy) sausages by pieces rather than by package loads.
The figurative last nail into Album’s coffin was an apple. In order to re-balance a reputation from the gravitational law (when fame was treacherously attributed entirely to Newton, and the apple got out of it with mere proverb “didn’t fall far from the tree.”) Taught by this crisis, this time the apple left nothing to chance and under its English pseudonym “Apple Inc.” brought the World the iTunes application. (which broke the album metric system for good). In Apple products, the music was suddenly available, God help us, by pieces. The world order has turned again from the head to its feet and you could buy (in the sense of the above analogy) sausages by pieces rather than by package loads.
 Expondo
Expondo underlying data analytics engines are so well-tuned that from over 1 million clients portfolio, incredible 40% of customers are so satisfied with what Outfitters have recommended to them that they choose to activate subscription. This works by sending items on a monthly basis that they have never seen before nor indicated any preference for them, yet they like them so much that they keep them. Clients have literally outsourced their wardrobe to the e-shop. And all this is happening in so taste sensitive and demanding industry as fashion is.
underlying data analytics engines are so well-tuned that from over 1 million clients portfolio, incredible 40% of customers are so satisfied with what Outfitters have recommended to them that they choose to activate subscription. This works by sending items on a monthly basis that they have never seen before nor indicated any preference for them, yet they like them so much that they keep them. Clients have literally outsourced their wardrobe to the e-shop. And all this is happening in so taste sensitive and demanding industry as fashion is. The industry, which has long been stumbling somewhere on the interface between small e-shops and (even smaller) off-line stores, is selling nutritional supplements (especially for bodybuilding or fitness). The Supplementer.com portal is a very interesting way of simultaneous (and synergistic) activity both in on-line and off-line; In addition to the private label, which is common in the industry and in CEE it is smartly operated by
The industry, which has long been stumbling somewhere on the interface between small e-shops and (even smaller) off-line stores, is selling nutritional supplements (especially for bodybuilding or fitness). The Supplementer.com portal is a very interesting way of simultaneous (and synergistic) activity both in on-line and off-line; In addition to the private label, which is common in the industry and in CEE it is smartly operated by  human movement. However, with the advent of new trends in mobility, these data points are taking on completely new fields of application. A much larger sibling of Instarea, the
human movement. However, with the advent of new trends in mobility, these data points are taking on completely new fields of application. A much larger sibling of Instarea, the