You may be surprised by this question. Because most of us have at most a choice between whether to take the test or not. (Some of them still have bad luck in this as well.) And the idea that at the testing point they will place several different boxes in front of you and offer you a choice resembles more of a street gamble scene with three cups and a ball under one of them. But close your eyes for a moment and try to imagine that you could really choose: By what criteria would you choose the test? Fastest? What’s the least painful?
I think most of us would choose the most accurate test possible. But that’s exactly the trap of the debate. As you will learn soon, each test has by its very nature 4 metrics of “quality”. So if you say you want a test with 99% “measurement quality”, without a deeper insight into matter, you can end up with 4 completely different tests that each are 99% “accurate”. (In addition, each time you repeatedly test the same person, you will get a completely different positive / negative share of among the tests). Therefore, this blog explains which of the 4 metrics will be most important to you and how high the metric value should be. The blog also explains why I solve this quality dilemma on a daily basis, though I don’t work with COVID tests at all. But let’s save that matter until the very end of this text.
Before I fulfill the above-mentioned promise of initiating you into testing accuracy, please allow me two short, personal notes. I have had this blog in progress for several weeks by now, but this week’s statement by the Slovak government that it wants to test the entire Slovak population (by antigen tests) has pushed me to finish it quickly. I believe that the information from blog(s like this) will be important for the discourse of the coming days (and one’s decision on whether to take part or not in this population test voluntarily). The second personal point is that today it is exactly 10 years since I started writing blogs! Unfortunately, there was no cake with candles. But as you can see, I celebrated blogging anniversary with, ehm, blog work. I can’t promise to keep myself blogging for another 10 years. But I’ll do my very best to make this (295th) blog, as interesting and inspiring a read, as more than half a million unique views of my previous blogs were. Now back to the tests.
4 success metrics
When we deliberate how well things works, we usually think in terms of % reliability. If we find out that something works at 90% (or more) percent, we usually stress down. It doesn’t occur to us that we should seek any other metrics of success. We simply expect it to turn out well in roughly 9/10 cases.
Therefore, the revelation that there are some other measures of success of a product or service, and even that there are 4 of those metrics, might seem like fate’s irony or pointless meticulousness. This confusion in our headarises from fact we do not look at things strictly in factual basis. Often, we forget that the very real state of something we aim to study may not be known; and we try to guess the real state out of someone’s observation. Such situations are common in our lives: think you and classmates playing in a school yard. Some of you broke a window and a class teacher comes to solve this window issue. 4 possible scenarios could occur: You didn’t break the window, but you still got rebuked by the teacher; you broke the window and were rebuked justifiably, but equally the possibility is that you broke the window and unfairly escape reprimand, or you did not break the window and was not rebuked. So if someone (in our example, a class teacher) tries to solve the case of a broken window, suddenly she has several goals to deliver: to reveal the real culprit, not to blame other children, but to make it clear that this is unacceptable to repeat again, …
No less of confusion it is even in science, when measuring or testing things. This is also evidenced by the fact that the scientists themselves named the method of solving such situations as the Confusion Matrix. Its simplest form looks like this:
In principle, it is a 2-by-2 chart (the wiseacres would say that it can be more than 2-by-2, but let’s not meddle it here). One dimension is the real state of affairs(he broke the window, he really has COVID, he really murdered, …) and the other dimension is what the test / observation / estimate said about the state (he was reprimanded, the result of the COVID test, the court found person guilty …). Combinations of these two dimensions create 4 possible states:
True Positive (TP) = a person to whom the test correctly estimated that a given phenomenon actually occurred to him (eg justly convicted)
False Positive (FP) = a person who is actually negative but the test falsely accused him of being positive (eg falsely accused innocent)
True Negative (TN) = A person who has been correctly estimated by a test to be truly negative in a given phenomenon (eg, justly acquitted)
False Negative (FN) = Wrongly marked as negative = a person who is actually positive, but the test did not reveal it and claims to be negative. (eg wrongfully released real offender)
By the nature of the matter, of course, we don’t mind TN and TP, because they marked things correctly. The fields of FN and FP are confusing the matter. However, for the correct assessment of the “quality of the test”, mutual relations among the 4 possible outcomes are also important. As result the following 4 metrics arise to enable complete assessment of the situation:
Overallaccuracy = the ratio of those for whom the test guessed their true state correctly, thus = TP + TN / (FP+FN+TP+TN)
Sensitivity = (Recall ) = Detection rate for those whose test really should have revealed the phenomenon = TP / (TP + FN). With 100% sensitivity, the test revealed everyone who was tested and was really positive. At 50% sensitivity, the test “forgot” to mark every second truly positive.
Specificity = Rate of correct marking of negative in those being with negative test result = TN / (TN + FP). With 50% specificity of the test, half of the negatives are erroneously marked as positive.
Predictive power of positive test = (Precision ) = Probability that the person is positive, if the test said so = TP / (TP + FP).
(The little secret of more informed is that there are actually more than 4 metrics, but the other (not mentioned here) metrics can be derived from most common (and here mentioned) 4 ones)
How to chose the proper test?
So what? Do you already have your favorite of the 4 metrics listed? If you think it is enough to have a high overall accuracy, you are dangerously wrong. Try the following example: You have 2 lie detectors, both of which are 90% successful in overall. However, detector A has the remaining 10% on top of the successful readings in the FP box and detector B has them in the FN box. In terms of overall success, you should not care about what you want to be examined on. However, the essential difference between A and B is: Whenever detector A is unsure, it will identify you as guilty, while B whenever it gets unsure will label you as innocent. So what? Still don’t care which one to take?
The whole selection matter gets complicated by the fact that different social processes/decisions require an emphasis on different metrics of success. With the broken window mentioned, the class teacher will probably primarily aims that this act does not go unpunished. (for moral reasons) Therefore, if the children deny the responsibility each and they try to cover each other, then teacher will (threaten to) punish all involved. In doing so, she is guided by maximizing the Sensitivity even at the cost of a low Predictive power of the positive. In other words, we prefer a few unwarranted reprimands over leaving anyone unpunished for a broken window.
On the contrary, Sensitivity is often the most important consideration in medicine (undetected internal bleeding is worse than incorrect suspicion of it), but for tests that lead to surgery, chemotherapy or other irreversible procedures, Precision is also very important. Having an unnecessarily amputated limb or a torn tooth is also not a top notch health care.
On the contrary, the presumption of innocence in our justice system is a pure focus on Specificity even at the cost of low Sensitivity. In other words, 10 acquitted criminals rather than 1 unjustly convicted. How painful to accept this is has surely experienced any democratic community.
To elicit correct decision, it is necessary to say what happens to testing if, some of test quality metric(s) are weak. If a decision-making process has a low rate of Positive Predictive Measure, it means that many people have been falsely identified as positive and this will significantly undermine the credibility of such a process (people will not complain if they are mistakenly declared innocent, but will revolt if many marked guilty are innocent, matter-of-factly). On the other hand, low sensitivity means that if something is to happen as a consequence of a positive test (eg treatment), many people will not get that, even if they deserve/need it. Thus, the costs and consequences of undetected cases kick-in. This might mean also as tragic things as unnecessary deaths in healthcare, or more preventable infections. Low Specificity, in turn, leads to unnecessary exposure to the consequences of a positive test, whether in the form of unfair imprisonment, unnecessary treatment, and stress for people who are labeled as (sometimes even terminally) ill, though they are super healthy. What is more, it might also lead to unnecessary financial waste (for example, when granting discounts or deciding to whom to send a offer letter with costly sample item). Finally, the low overall accuracy is bad in itself and says that you probably have the wrong test, first place.
What to take out of it for COVID testing
The development of the COVID pandemic has so far brought 3 basic types of COVID tests to the table. They differ not only in their testing approach, but also, unfortunately, in which success metrics they emphasize. But it is not the negligence or malice of their creators. Simply given tests are intended for different situations, where this or that metric of success plays a unique(ly important) role. For your basic orientation, I compiled a table with 3 basic types and their success metrics:
A cursory glance at the table shows that the overall best accuracy is achieved by PCR test and their Antigenic cousins (selected for mass SR testing) have the worst scores. To stay on the correct terms, it must be said that antigenic tests are the only tests with which such a extensive population testing can be physically performed. It would take more than a month to evaluate PCR tests for the whole country (even with the effort of all forces and foreign help) and cost would mount to at least 10 times more than Antigen-variant. Antibody tests would be cheaper and more feasible than PCR, but their primary goal is to confirm the course of COVID disease in suspects who have been infected for at least 2-3 weeks (which is not exactly a tool to isolate and prevent the spread of the virus). Given the possibilities of the government, it cannot be concluded that they chose antigenic tests (in reality, there was no real, feasible option). However, mass testing in Slovakia with this tool would mislead about 80,000 households as to whether or not they have COVID. Almost 50,000 of them would have the virus and be reassured that they don’t and they can do everything the old way, after all, they had a negative test. If you live in an 8-storey block of flats, on average at least one family in your gate would be quarantined undeservedly. Whether you should join this government mass testing action (if you have a choice, first place), I will leave to your discretion. So far, the risks of participating in such a test have been little pointed out (eg waiting in line with potentially infected people, traveling to the testing site, …), but their real impact will depend on how the whole event is logistically organized. Up to now we have only heard that “it will be like elections” on the logistics account. Well, if all this is to make impact, it remains to be hoped at least for elections other European Parliament vote (where Slovakia has about 20% turnout). When deciding whether or not to go, I especially wish you calm head and a bit of common sense. I hope this blog also gave you some more food for thought. If you still have 2 minutes more, the next paragraph depicts how interestingly I come into contact with above stated 4 metrics of success at my work.
What does it all have to do with my job
For regular readers of themightydata.com, I bring a few more lines about what are the most important conclusions from Confusion Matrix for our work with data. Majority of models predicting behavior have the nature of (binary) classifiers = indicating whether something is this or its opposite. However, that means that classifier essentially resemble (COVID) tests. Hence, the above 4 metrics of success also come into play when deciding which prediction model to deploy in the final production. Most beginners make the mistake of looking only at Accuracy metric. This is probably due to the fact that it is the default metric in many model evaluation statistical packages. Those slightly more advanced recognize that in reality picking the right production model is more a fight of Precision versus Recall. Why so? Models are usually quite confident in apparently positive and apparently negative individuals. Their issue remains where to lean in the middle unclear opinion waters (do you still remember lie detectors A and B?). However, what often confuses even the advanced analysts (don’t worry, after all it’s a Confusion Matrix :), that in some models Recall is more important than Precision. Have some doubts?
Well, imagine a model that tries to predict the churn of clients to offer them some small relief and persuade them to stay with our customers. For such a model, it is much more dangerous if it does not identify some actually departing clients rather than if it undeservedly labels some satisfied clients as churners. Therefore, optimizing the model for Recall is much more important here than taking care for Precision. On the other side of the coin, if we do an X-sell campaign where we send a free product sample, good Precision may be more important than Recall. If the campaign is successful (a large percentage of contacted purchases), we will easily get the budget to extend into next round that campaign (which will also address those (wrongly) marked as less likely to buy). But if we (due to low Precision) in first wave of campaign rather send an unnecessarily large volume of product samples (in attempt to capture everyone), the campaign will be immediately in red numbers, considered a loser and spared of chance to correct for that.
That is reason why I have to regularly decide in my work which of the 4 success metrics we will optimize for. So, similarly as with COVID tests, we strive to choose the greatest good, or at least the least evil. This can only be done, of course, only if you inspect all the Confusion matrix metrics for every prediction model; which I would strongly like to encourage you to. On top of it, comparing FP, TP, FN and TN groups can also provide hints on how to improve the model itself. But that’s something for separate blog post next time. Thanks for reading that far and make smart choices of (not only) WHICH COVID TEST would you take! Stay Healthy!
Ľudia, čo ma poznajú dlhšie, vedia, že na označenie knihomoľ sa nemôžem príliš urážať. Čítam naozaj rád (a pomerne veľa). Avšak len tí najbližší vedia, že si dávam každoročne predsavzatie prečítať za rok viac ako 10 000 strán kníh (nad rámec iných zdrojov ako časopisy, blogy či novinové články.) Za posledných 11 rokov sa mi nepodarilo tento záväzok splniť iba raz. Tohto roku sa mi darí podozrivo dobre (musím si zaklopať), zhltol som už 32 kníh. Aj keď čitateľský výsledok zachraňovala najmä letná dovolenka. Počas prvej vlny Korony totiž séria COVID článkov (s viac ako 30 000 slov) tu na Mocnedata blogu pohltila celú moju energiu. A tak knihy boli ten prepotrebný recharge.
Knihy, ktoré si kupujem, starostlivo vyberám. Vďaka tomu tie príjemné prekvapenia výrazne predbiehajú sklamania. Kníh však stále vychádza (na svete) veľa a tak nájsť tie skutočné poklady naozaj vyžaduje určité úsilie. Rozhodol som sa preto podeliť s Vami o to najlepšie, čo postretlo mňa zatiaľ v roku 2020. (Na oddych čítam aj knihy, ktoré sa vecne do okruhu MocneData tém nehodia, zhrniem tu však iba tie, ktoré predpokladám, že by mohli byť inšpiratívne aj pre čitateľov MocneData.sk portálu):
Competing In The Age of AI
Zameranie: Dáta, Dátová Analytika, Biznis
Kníh o algoritmoch Umelej inteligencie a ich aplikovaní nájdete neúrekom. Ako to už býva, ako náhle je nejaká téma super populárna, mnoho autorov sa chce zviesť na vlne. To je dôvod, že väčšinu AI kníh, ktoré dnes dostanem do rúk, po preštudovaní obsahu (a začítaní sa do pár kapitol) sklamane vrátim naspäť do police kníhkupectva. Šliapnuť vedľa nie je aktuálne vôbec ťažké. Táto kniha ma však, naopak, úplne pohltila. Doručí totiž presne to, čo sľubuje jej nadpis. Systematický návod, ako zaviesť AI do akejkoľvek firmy či organizácie. Vysvetľuje princípy, ktorých sa držať, ponúka checklisty aspektov, na ktoré netreba zabudnúť. Nenájdete tu žiadne floskule alebo helikoptérové rady. Aj dielčie kroky sú jasne štrukturované a hneď na začiatku naozaj uvidíte, kde sú hlavnné miesta pre zasadenie AI riešení vo vašej konkrétnej firme. Text je navyše tak písaný, že sa nebudete vedieť dočkať dalšej kapitoly, aby ste pochopili, čo má byť tým ďalším kúskom mozaiky. Na základe inšpirácií z tejto knihy som napísal pre top manažment našej firmy plán AI inovácií na ďalšie roky.
Ak sa hrá futbalový zápas, tak v hľadisku je každý elitným trénerom a futbalovým expertom. A keď sa začne disktuovať o vesmíre, každý sa kasá vedomosťami z čias, keď Pluto ešte bolo (mylne) považované za planétu. Darmo, rychlokurz geniality sa v astrofyzike robí naozaj ťažko. NeiL de Grasse Tyson sa však k tomu priblížil tak blízko, ako to ide. Ako už samotný podtitul naznačuje, rozhodol sa totiž napísať knihu o vesmíre pre ľudí, ktorí nemajú čas (si skôr trpezlivosť) prelúskať sa buchlami, vzorcami či záplavou vedeckých článkov. A urobil to naozaj bravúrne. Kniha je písaná tak, že neodradí od dočítania ani úplneho laika (ktorého fyzika mátala už v škole.) Navyše, posunie vašu mieru poznania vesmíru o toľko ďalej, že nepohoríte ani na prvom rande s astrofyzičkou/-fyzikom. Naozaj jedna z tých kníh, čo stojí za hriech. Vyšla dokonca aj v slovenčine, tak prikladám link na obe jazykové mutácie
Nie, toto nie je kniha o cyberzločine, či mapovaní Tmavej enmergie či Tmavej hmoty. Nie je to ani kniha o čiernej mágií. Aj keď vlastne možno …
Dátová analytika je neraz tak trochu aj mágiou. David J. Hand však komunite dátových analytikov (a s dátami pracujúcich ľudí) urobil veľkú službu. Systematicky totiž zhrnul 15 rôznych dôvodov, pre ktoré nemáme dáta kompletné či dostupné pre analýzu. (Čoho dôsledkom je legendárny GIGO efekt.) Tá podstatnejšia časť posolstva, ktorú sa aj ja snažím často vysvetliť (hlavne) začínajúcim dátovým analytikom, je: Za koľko z tých 15 dôvodov si môžeme ako dátoví analytici sami? Knihu možno poňať aj ako kuchárku toho, čo by ste v dátovej analýze nemali opomenúť a čoho sa naopak vystríhať. Čo si vážim na autorovi najviac, je fakt, že na každý z 15 možných dôvodov (,kde dátová práca “zakopáva”) autor ponúka aj jasné návrhy riešenia (či prevencie). Jednovetová recenzia tejto knihy by znela: Povinné čítanie pre tých, čo za živia prácou s dátami, inšpirácia pre kohokoľvek, kto nechce podľahnúť (neodbornej, či účelovej) manipulácii s faktami.
Neviem, ako sa to podarilo, ale tohto roku som mal šťastnú ruku na prekvapivo veľa zaujímavých filozofických kníh. (Možno starnem.) Aby bolo hneď na úvod jasné, filozofické traktáty znášam podobne dobre ako väčšina populácie. Teda tak po 5 stranu. Potom zväčša pregúlim očami a kniha sa prepadá v čítacom poradovníku. Alfie Brown ma však svojou knihou upútal. Nielen tým, že ju spravil znesiteľne krátku, ale najmä tým, že si vybral tému, nad ktorou som už aj ja premýšľal. Je súčasná Netlix vlna a Hranie hier na mobile len zabíjanie času? (nad ktorým my, knihomoli, môžeme pohrdovačne predniesť svoje “Pchá!”) Alebo ide o legitímne a zmysluplné trávenie voľného času, ktoré zostáva generačne nepochopené? Argumentačne a filozoficky podložená rozprava o tejto téme ma nielen vtiahla do čítania tak, že som si nevšimol, ako ďaleko som za 5tou stranou. Objasnila mi aj postoje niektorých ľudí z môjho okolia. Možno mi budete po prečítaní nadávať, ale fakt by som vám to odporúčil si prečítať. Autor navyše napísal aj ďalšie podobné dielo na trochu inú tému, ktoré je na mojom reading liste ešte do konca roka. Tak prípajam link aj k tomu druhému dielu.
Ak by ste poznali Andreja, asi by ste nepochybovali, že jeho kniha na tento zoznam patrí. Ale keďže ho zrejme nepoznáte, skúsim vám priblížiť, prečo jeho kniha naozaj stojí za prečítanie.
Žijete ako chlapec na sídlisku na strednom Slovensku. Dopočuli ste sa, že v takom Nórsku by sa dali zarobiť skvelé peniaze. Tak si vygooglite nejakých Slovákov v Nórsku na Facebooku, “rozbijete prasiatko” a kúpite si letenku do Nórska. Vystúpite z lietadla a Nórsky sen sa môže začať …
… až na to, že váš Slovenský mobil nemá roaming, neviete po nórsky, nemáte vysokú školu, nikto vám neche dať prácu, prepleskli vás škandinávske ceny, nemáte nikoho blízkeho, vaše úspory sa okamžite rozplynuli a začínate mať povážlivé zdravotné problémy.
Nie, to nie je scénar B-čkového dobrodružného románu. To je skutočný príbeh Andreja Tichého. Ktorý sa, snáď mi to priateľu prepáčiš, dosť naivne vybral do Nórska. Hoci samotný príbeh (z ktorého nechcem vyzradiť najpikantnejšie scény) by bol hodný filmového námetu, táto kniha má oveľa silnejší odkaz. Ukazuje na to, ako naozaj chcieť niečo dosiahnuť. Ako sa nezlomiť a na čo všetko sa pripraviť. Ale hlavne ako nakoniec uspieť a splniť si (v podstate nereálny) sen. A ako pochopiť, že to je len prvý stupienok v dlhom kariernom a rodinnom živote.
Nie, nechajte sa oklamať šibalským názvom knihy. Toto nie je cestopis, ani návod, ako sa dostať na ropnú plošinu. Toto je energetická vzpruha, ako dosiahnuť svoje sny. Navyše vzpruha, pri ktorej sa zasmejte aj si zahíkate.
Iste ste sa už ocitli v situácii, kde išlo o veľa. Hádka s partnerom, požiadavka o zvýšenie platu, obchodné rokovanie alebo dieťa, ktoré sa nevie vspratať do kože. A keď si spätne prehrávate tú situáciu, hlava sa nestačí čudovať, čo to ústa hovoria. Kde hľadať radu, aby sme si to nabudúce (prinajmenšom) sami nekazili?
Hľadať rady o vyjednávaní možno u rôznych profesií. Niektorí vám odporúčajú hrať neústupných tvrďasov. Iní vás nasmerujú k tomu “aby ste dohodu s oponentom smerovali niekam doprostred rozpätia”. Čo si však o optimálne stratégií vzjednávania myslí Policajný vyjednávač, ktorý rieši rukojemnické drámy a únosy? Má ponúknuť protistrane zabitie polovice rukojemníkov výmenou za to, že sa útočník vzdá?
Chriss Voss je absolútna svetová špička vo vyjednávaní s ozbrojenými útočníkmi a teroristami. A ako policajný vyjednávač vždy musí hrať na to, že on vyhrá všetko a terorista nedostane skoro nič. Preto je zaujímavý jeho pohľad na to, ako viesť vyjednávania tak, aby na vašej strane zostal celý jackpot. Ak vám to príde odpudivé (až nefér) pre bežný život, pozeráte sa na to rovnako ako ja, kým som knihu neotvoril. Verte mi však, kniha nie je návodom, ako druhú stranu ošklbať. Je to súbor rád (popísaných na konkrétnych prípadoch), ktoré vám umožnia ísť aj za 50:50 dohody. A pritom neuraziť ani nepodraziť oponenta. Popísané postupy sú však rovnako užitočnou obranou proti zdatným súperom, ak aj sami nechcete aktívne zatlačiť. Kúpa tejto knihy sa vám násobne vráti. Už na najbližšom hodnotiacom pohovore alebo hyisterickej scéne vašej ratolesti.
Ako som písal v záhlaví tohto blogu, knihy krásnej literatúry do odporúčaní na tomto blogu zvyčajne nedávam. Pri tejto knihe však veľmi rád urobím veľkú výnimku.
Kniha Tom Roba Smitha ma fascinovala tým, že veľmi dlho (vyše sto strán) som nevedel odhanúť. aký žáner vlastne čítam. Chvíľu som mal pocit, že čítam historický román, či literatútu faktu o sociálnej situácii v povojnom Rusku. Alebo detektívku? Ak vám toto moje zmätenie príde nepochopiteľné, tak vedzte, že autor tak pútavo mieša tieto tri línie knihy, že je vám to vlastne úplne jedno. Chcete ďalšiu a ďalšiu stránku, nech je to ktorekoľvek z nich. Inými slovami kniha tak verne prepája opis spoločenskej situácie so životom postáv, až … až zrazu zistíte, dopekla, veď ono je to detektívka. Vrah sa začína nápadne podobať na niekoľko postáv. Začínate mať istotu, kto to asi je. Ale spoločenské zriadenie ho vlastne nechce vypátrať, tak ako bude spravodlivo potrestaný? Dieťa 44 (mimochodom prvý diel trilógie) je skvelá a pútavá kniha na jesený večer aj k opaľovaciemu krému na lehátko. Proste si to užite.
Jadrom mnohých problémov biznisu je, že sa na aktuálne dilemy nazerá metódami spred 20 a viac rokov. Rozhodnutia totiž robia ľudia, ktorí študovali v čase, keď dané témy boli horúcimi novinkami. Ako však dovidieť za horizont? Ako správne prečítať, čo bude IN v najbližších rokoch? Ale hlavne, ako inovovať skôr pomocou “calculated bets” ako cez “plug and pray” projekty.
Hoci Rita McGrath patrí (aj v mojej rozsiahlej knižnici) medzi neznámych autorov, rýchlo si získala moju priazeň tým, ako pragmaticky pomenúva slabé miesta biznisu a skutočné záplaty na tieto diery. Nebojí sa ísť proti mainstream prúdu, takže sa dozviete, že trhový podiel je zastaralá metrika, že skutočné inovatívne firmy sú tie, ktoré na to nepotrebujú zamestnancov alebo že Netflix dlho tápal v tom ako prejsť na predplatné. Nehľadá ikony ani hrdinov (ako je tak bežné pre Amerických biznis autorov). Naopak, servíruje dobre štruktúrované rady, ako systematicky inovovať, ale aj čo sú často opomínané úlohý lídrov v tomto procese, či ako nepodľahnúť tlakom okolia.
Je to hutné čítanie a pripravte sa na to, že budete odbiehať od knižky k poznámkovému bloku či klávesnici si zapísať podnetné nápady. Podctivé čítanie tejto knihy teda zaberie viac času, ako by jej (inak štandardná) hrúbka naznačovala. Ak však vediete nejaký team alebo (spolu)zodpovedáte za stratégiu či smerovanie nejakej firmy, moje odporúčanie si s chuťou užijete.
Ak ste členom komunity MocneData už dlhšie (mimochodom stať sa ním môžete bezplatne tu), tak viete, že svoje čitateľské odporúčania som dával aj po iné roky. Tu sú niektoré z nich:
I have devoted quite a few blogs to the topic of COVID-19 and its impact on our lives, especially in the community of my mother tongue. To read some through Google Translate, go reading here. However, the topic I want to talk about today has its implications in many countries around the world, so I decided to compiled this post into the English version as well. In the next lines, I would like to find together the answer to question if Corona virus WILL KILL YOUR WORK (or business).
Not every bankruptcy is the same …
Let me make one important point before describing the sectors that will receive the worst ‘slap on their face’ during this epidemic. Many people may (and will) lose their jobs during this crisis. Possibly, even in companies from industries completely different to ones I mention in this article. However, this is due to the fact that any (economic) crisis is also a sieve through which companies, built only for good times, do not make it to swim through. As my boss typically said: “When the tide recedes, we can see who had a swimsuit and who was swimming naked.” Running long-run business on low margin can work in all-is-booming times. In economy shocks like now, this will, literally, break your neck. After all, to withstand two-month sales shortfall means to have a reserve of merely 15%. So let me ask a slightly cheeky question: “How responsibly does the management lead the company if it does not have a “pillow” (or the possibility to bridge revenues with a short-term loan) for at least the given 10-15% of Sales?” Thus, yes, anyone can go bust within a crisis. However, in the following paragraphs, I would like to address those cases who are even not to be blames. In other words, those who might end up in sorrow corner (almost) no matter what they choose to do differently. The club of, sadly, innocent but in deep s….. (struggle :).
Gloomy prospects club
As you will read on in a moment, there are certain commonalities among the individual “victims” of the COVID-19 crisis. However, in order for our discussion to have a proper turn, let’s depict a few concrete examples:
It should come as no surprise that in the very beginning of the lists of “convicted” sectors, there are activities that require/assume presence of a large number of people. Like any team sports that cannot even happen. Zero matches = zero sportsmen revenue and it doesn’t even matter how they were collecting (admission, TV rights, …) reward for their content. The film industry is in a similar situation. The shooting of big blockbusters is incompatible with social isolation. Another imaginary nail is hammered into the industry’s chest: even if film studios found a way to produce their content, significant part of their sales are through cinemas that do not open either. Let’s not forget, that mentioning Cinemas, we represent, of course, also Concert and Event Agencies, Music Festivals, Theaters (and all those businesses renting halls and apparatus or serving catering for the events). In fact, Conference Tourism sits just inch away on the very same shelf. Not exactly the same, although remarkably similar, is the situation in gastronomy. Cafes, Restaurants, bars and discos, they all run on crowds. And on we could go staggering from one economy area to another. However, let’s stop calling shots into the dark, let’s give this overview a bit of the frame (not to leave mistakenly some important verticals out of list).
Where does it blow from …
As I have already indicated, the destruction brought by COVID-19 is led by certain common features. The first one is represented by what the direct consequences of this epidemic are. As we described in the Epidemiology Crash Course [Slovak language only], a key factor in the epidemic (and its suppression) is the reduction in people encounters. Therefore, all industries whose 1] product itself consists of gathering people (eg playing of the philharmonic or a football match) or can only be produced by amassing people (e.g. production of a feature film, transporting in public transport or eating in a restaurant) are therefore automatically in “off-side”. There is no form of product replacement or hurdles bridging for these sectors. Pure bleeding.
For similar reasons, albeit in a completely different way, the sectors that 2] need a household for their performance are also affected. It is probably difficult to invite a painter or parquet worker when you are sitting as a quarantined family at home to avoid contact with people. The fact that flats and houses have become our sanctuaries against Corona-virus also means that they are inaccessible to various crafts, upgrades or reconstructions. There is also no alternative way to do these jobs, because the painter, ehm, somehow can’t work from home. At the same time, an interesting sub-branch of this second principle are real estate agencies, moving services and subleases. In the apartment where the tenants live in the quarantine, there will hardly be any flat seeings . Also, at this point time, no one voluntarily decides to move. Hence, the flat rental market (and their brokerage) also likely went almost to full freeze.
Here comes the third group of jobs, which may not need to gather a high number of people at the same place at same point in time, but 3] must be performed in the form of human-to-human encounters and has a high number of daily repetitions. As a result the product/service supplier of acts as the risk element while being “a connecting bridge” for a high number of different people meetings per day. This set includes hairdressers, taxi drivers, cafes, but also hotels, financial intermediaries or advisers, but also post offices and public market stalls. In this very group, complete income bleeding can be (to some extent) prevented by changing the business model to “take-away” or via video forms, or through combination of daily frequency reduction and simultaneous high protection with masks, disinfectants and other protective measures.
We danced all the hall-way to a group that is not primarily affected by the epidemic itself, but they build their 4] business model on people’s (daily) rituals. For example, the daily press sells its editions to people who go to work (either office subscription or sold in news stall on the way to work). Remember this point when you will read in later paragraph about factor B], because out of the printed periodicals, magazines are significantly worse than dailies, as only few weekly magazines have their own web versions (in Central Europe). Similarly, there are restaurants living only out of lunch menus. Finally, this group also includes travel agencies (and our recreation habits).
We are approaching the end of the list with the so-called 5] non-essential goods, i.e. things that you do not need immediately and therefore endure a delay of a week. This includes the purchase of new shoes or carpets, a visit to the escape room, as well as corporate bowling and other forms of physical team-building.
At last, there is one completely inconspicuous (but it will quite numerous) group. The companies that (especially close to borders) 6] have suppliers (or customers) abroad and due to restrictions on movement they either do not receive goods (food store that has the nearest larger city closer in neighboring state rather in own state) or to whom customers will not have means to travel (e.g., the legendary Polish or Austrian markets).
Mitigating or worsening conditions
As is often happens in our world, nothing is black and white and (similarly to certain sex story) it is rather many shades of gray. Hence, individual sectors can improve or worsen their starting position with a set of mitigating or, on the contrary, aggravating circumstances. No matter how pathetic it sounds: After all, everyone has it partially in their hands. At least a bit.
One of the most important mitigating factor is option A] of the contact-less form of the business. For restaurants, the second leg resides in a delivery service. For pharmacies, it is the sale “through night” windows, or the food delivery service from large chains. A higher form of risk distribution is the over-distance form of business, which includes the transition to an e-shop in the case of physical products (remember the weekly magazines?) or the transition to video-meetings in the case of services. This will also show the flexibiliy of businesses to fight own fate. Basic video conferences are currently completely free around the world (see for example blizz or zoom). The e-shop can also be used for any physical goods and there are several “turnkey” solutions (eg Shoptet), as well as instruction blogs on how to start an e-shop. The last mitigating lever is the existence of the C] subscription model implemented in business. As I wrote in a previous episode, this is best explained on difference between a gym and a restaurant. Both will be yawning with empty rooms these weeks, but gym will probably survive thanks to its membership subscription model. Sadly, most restaurants do not have some form of subscription in place.
On the other side of the sun, there are circumstances that, in turn, hammer even more nails into the coffin of given business. Perhaps the most important is the Z] transience of consumption. In practice, even if the restaurant manages to survive two months (for example with a loan), when it opens, it does not have a chance to catch up with clients’ “missed” purchases (if it did not run on too low of the level before the crisis). No one will have 3 steaks for same lunch in June because they missed them in March through May. A similar problem, but on the other hand, is the Y] transience of capacity. If the painter needs 1 day to paint the apartment, even if he has more orders after the quarantine, he still has the same 24 hours, so he cannot paint 3 apartments on the same day to make up for the loss of previous months. The X] position of intermediary also plays a special role in aggravating circumstances. If you are a real estate broker, then your risk is doubled, because you are also in danger of unavailability of apartments for rent and at the same time of lack of interest of potential tenants (for example, due to loss of income).
So, what are my (job’s) chances?
So how do you assess your chances in midst of the Corona crisis? Well, for you to find out, first go through points 1] to 6]. Select those, that apply to you. If you happen to meet more of them simutlaneousy, honestly, I probably wouldn’t volunteer to step in your shoes. After that see if you can alleviate your burden with applying mitigation of any of A] to C] points. Be careful, even if you didn’t have any ot them before the crisis, it’s still time to seize the opportunity now. Including planning point the C], which often companies so badly underestimate. If you write to loyal clients and ask them to “subscribe to future consumption” or some form of symbolic purchases for which they will not receive (full value) the goods (s), you will be surprised that there are those who understand your situation and are happy to help.
At last, it is tome to scan the aggravating circumstances of X] to Z] of your job/business, too. Not so much as to mourn your situation, but so that you can choose the right plan to emerge from the crisis. Because the world will not be the same as before the crisis, when we gradually emerge from it. On how to grab life by the brighter side of its mantel, we will soon tell more in the next part of our Corona blog series. Until our next reuniting, I keep my fingers crossed for you(r job) all.
Quantum computers are an important discovery and they will have equally important impact on human knowledge as the invention of electricity or radioactivity had. This is so (especially) because even smaller quantum computer has potentially larger computational effect than all computers in the world combined! Where does a quantum computer (QC) take a billion times multiple of classical computer’s power? Is it possible for it to run completely without electricity? Are QC’s universal or useful only in a narrow industry? Which professions working with the computer today should eye a quantum computer, and whom would the QC evade for the rest of their lives? All of the above (and a bit more) you should find out in the following lines.
Classical Computer (CC) vs. Quantum computer (QC): Can we tell them apart?
Try to think for a moment: What do you know about Quantum Computers? When I asked colleagues and other people in my surroundings about what they knew about quantum computers, they mostly told me that: 1] they’re faster, faster than Classical computers, but they haven’t yet mushroomed (for unknown reasons), probably too expensive (?) and they are being worked on only in research departments of universities and major digital Titans (like Google or Amazon); 2] Their performance is measured not in GigaHerz, but in weird Qubit units; (what is it?) 3] They use some kind of quantum physics and so it’s complicated enough that nobody actually understands how they work; 4] They can calculate things that we cannot otherwise calculate (but no one can name any specific one). And that is the end of the line, usually. If I were to summarize it into single sentence, I would probably say that general (or even expert) public currently perceives quantum computers as: “Complex, particle physics-based black box that counts faster, but few understand it and thus it is not yet wide-spread.” Well, my hope is that after finishing this article, you will also condescendingly lough at this answer. It is the very shallow actual knowledge of such an important technology that made me write this blog.
The essence of Quantum computers indeed is stemming from laws and processes of Quantum mechanics, the branch of physics that we really mean when we utter “… we do it quickly, it’s not nuclear physics!” Quantum mechanics really is such a complex branch of physics that lending quote from famous Czech movie ‘Jak basnikum chutna zivot‘ [How Poets’ Lives Taste] : “Only God knows the subject for A, the Nobel Prize winner for B or C, the university professors for D, their best students might score E and its (F)AIL for everyone else! ” (disclaimer: in the original film, the statement was about Chemistry). As a result, when you open a book on QC, complicated physics formulas and equations (on which my undergraduate roommate jokingly remarked: “Filip, I have been redrawing the figures the whole lecture, because you can only take notes, if you know what you are writing about“) overwhelm you on the very first pages. Consequently, the understanding of QC (and their use) narrows for most of us to the few sentences of the previous paragraph.
And pity it is. Yes, QC can be (quite densely) discussed in the form of complicated schemes and formulas. But it can be done differently, too. And is this blog-post’s mission: To give you the essence of quantum computers without complicated equations and without assuming that you have passed the exam on differential equations or linear algebra. If it still fails to do so, I apologize in advance. However, it would be nice if you to give me after reading a short feedback (to info@mocnedata.sk) on whether it succeeded in doing so. Last thing before we start, let me do a short disclaimer: Although I have successfully passed the above tests and are therefore have privilege of comprehending the complicated equations, I do not make Quantum Mechanics for living. Therefore, if you are a researcher in this area, forgive me the simplifications made in the next paragraphs. They stem from either trying to be readable to wider masses or from the fact that some nitty-gritty’s are beyond my own power. (after all, I’m not a Nobelist nor a college professor :))
Where it all had started
Many of the areas of science that even a primary school pupil can master nowadays have not been known for thousands of years of human existence. For example, such trivial things as -400 (negative numbers) have long been beyond the understanding of not only ordinary people but also contemporary scientists. (Seriously: have you ever seen a negative number in Roman numerals?) The reason was that back then people used mathematics (and other sciences) for practical purposes only. And until the invention of accounting, the negative number had no point in life. In common life you simply cannot see -5 apples. One of those mathematics areas “only destined for selected few” were complex numbers. Even René Descartes spoke of them with mockery, and it was only thanks to scientists like Gauss or Euler that they have made it to the Earth. As complex numbers are an important building block of quantum computers, let me briefly approach them here. They will be very instrumental for understanding the “distinctness” of QC.
Mathematics has been associated with the solution of equations since ancient times. While we, as humanity, counted only simple equations of 1 variable, each equation had a solution (or clear evidence that it could not have one). However, when we went into the calculations with circles (and other conic curves), we found that some of our equations suddenly had no solution (and it wasn’t even obvious why they shouldn’t have them). For example, the simple quadratic equation x ^ 2 + 2 = 1 (which we all learned to solve, and therefore I give it here as an example) does not have a solution in the set of real numbers, since the solution would have to be the square root of -1 (because x ^ 2 = -1). And that cannot be calculated. Or can it?
In ancient Greece, the square root was defined (by Pythagoras) as the diagonal of the rectangle (e.g. the square root of 5 is the diagonal of the rectangle with sides of 1 and 2) and each line ( even diagonal) must be larger than zero. This burden has been on our shoulders for more than 2,000 years, until someone said: What if we imagined an virtual (third) dimension in which any 2D object could be rotated by some angle. Like an arrow drawn from the center out on the right page of a book with thin, translucent leaves. As you turn the page of the book, the same arrow suddenly – though it has not changed at all – points in the opposite direction (from center to left). If we take the arrow as a shift on the map by 1 length unit from point A to B, after reversing suddenly we have a shift of -1 (that is the same length, but in the opposite direction). Somewhat analogically, a diagonal of a square root of -1 can be formed. It is the angle of rotation in the imaginary third dimension that is the essence of complex numbers. In order to make it easier to calculate, a unit of rotation (= a quarter of circle rotation) has been chosen, which (after some trigonometric transformation) is labeled as a lower case “i”.
Here we can abruptly stop our short trip to mathematics, as the “hiking track” further continues through ugly cosines, sines and large matrices. However, two more things are important for our further discussion of quantum computers:
A] There is infinity of angles under which I can gradually turn the page of the book, each rotation resulting into rectangle’s diagonal of a “different length”. Thus, if I start to rotate (and connect) simple things in an imaginary space, the (computational) difficulty in determining all possible states of rotation steeply increases.
B] In physics (especially quantum physics) some objects (namely small particles) actually behave in a way that fits the domain of complex numbers. Thus, what began as an human urge to find a solution for each quadratic equation, later has proved to be truly useful for describing the real life of nature around us.
OK. But what role do complex numbers play in quantum computers?
The main “weapons” of Quantum computers
Most of us use classical computers somewhat naturally. We are used to take a laptop and open it on a train or airplane. The notebook (unless it has run out of battery) obediently executes any calculation command. Since most common users’ needs are a “piece of cake” for the ever-increasing performance of computer hardware, you probably never thought about the operational limits of a classical computer (maybe beyond the laptop battery). Although we are experiencing a golden age of computer development, and under (unwritten) Moore’s law, the performance and memory capabilities of available computers are literally multiplying year on year, there is indeed a physical limit of computers. For conventional conventional computers to run they need to rewrite ones in the memory to zeros and back. The smallest unit of their memory is called BIT. (The byte and thus the mega- or giga-byte are somewhat larger cousins of BIT). The so-called Lendauer’s bound determines the minimum amount of energy required to overwrite one bit. Thus, nature had set a strict limit on what is the least amount of energy (read electricity) it costs to count things. When we hit this limit, we will no longer be able to increase the performance of computers in other way than “burning” more electricity. And since our electricity sources are limited, we will inevitably encounter an upper limit of computing power one point in time. Although this upper limit will never bother us for our trivial tasks (like watching a video or sending an email), there are already scientific calculations (mostly in space and encryption areas) that have indeed already encountered theoretical limits of classical computer calculations. If we, as humanity, want to bypass the physical ceiling of classical computers in future, we have to come up with a computer that can count without having to rewrite zeros and ones. This is exactly what Quantum computers can.
The second significant limit of classical computers is that when calculating (e.g. multiplying) they must first store all the inputs (numbers that they multiply), then use the free parts of memory to perform the calculation (something like multiplying beneath each other on paper) and finally save the result of the calculation (the final product) in another part of the memory. Even worse, if you want to check your computer, you must save all the inputs and outputs of the calculations, otherwise you won’t be able to look back whether the result is actually the correct product of the numbers. This brings the limitation that a considerable part of the memory (and performance) of a conventional computer is continually tied to storing the already executed (or currently running) steps in order to track their progress. Alternatively, to ensure that the computer will be able to resume the task if something interrupted it. The reason why classical computers have been designed this way is that it allows them to theoretically calculate any computational task. However, the down side of this design is that calculations where computational demands grow exponentially (insiders know geometrically is enough even) with the number of inputs (such as lotteries or sorting things) cease to be realistic. Password protection is a good example. Each password can be broken by “blunt” trying all options around. However, if you have a sufficiently long (and varied) password, it can take years to decades to break it down. So it is maintained that by the time that someone breaks it you would have changed your password already anyway. But what if there was a new type of computer that does not need to keep continuous inputs and can jump from typing straight to result? Sounds like magic or science fiction? Well, this is how quantum computers work.
With a bit of irony, one could say that we were not ambitious enough in the construction of classical computers (CC). The CCs have been designed in a way that they always deliver only one alternative result at time. On punch cards (yes, the first computers recorded the result on a paper tape using a pinhole system, something like a primitive version of Braille or a paper woodpecker) one could only write one value at a time (and place). You needed another punch card to write another value. Over time, we have compressed the writing technique so that today we can insert billions of meters of punch tape into a few cubic centimeters of a USB key, but the principle of one value at a time (and at one place) has been preserved. The difference of quantum computers also results from the fact that one QUBIT (quantum BIT) can theoretically represent a huge number of different states (using complex numbers). It represents the physical nature of the particles, which themselves have countless states. The difference dramatically alters QC’s memory requirements, while allowing you to work more efficiently in modeling processes, in which things can end in large variety of states.
How quantum computers actually work
Well, it sounds all pink and incredible. But how does a quantum computer actually work? Is it the same “iron box” we’re used to on our desks? The unit of quantum computer power is QUBIT (= quantum bit). Since QUBIT must predominantly be able to function without a constant supply of electricity (remember the Lendauer constraint), QUBIT has to physically be modeled as an object that can change its state, retain its value and behave according to complex number manipulation rules (as we described in introductory part of the blog). In our physical, real world, atomic particles best meet these requirements. Therefore, although there are more technological approaches to creating QUBIT, the ions, polymer particles, photons, or silicon (and various other) atoms are most common choices. As the size of these particles is at least a million times smaller than the size of smallest conventional PC components, you would fit a very powerful quantum supercomputer under your nail. (spoiler: few lines down you will find out that it would be freezing cold)
IBM QUANTUM COMPUTER
The principle of QUBIT itself works in a way that a particle can have different energy levels (e.g. manifested by electric charge, speed of movement or other properties). Using microwave radiation or (laser) light beam, you can “poke” a given particle remotely to gain or lose some energy. If you select energy levels distant enough from each other (which ensures that a particle has almost no chance of moving between the two states on its own), you can use those particle states as zeros and ones in the calculation. Something like having a thermometer in a sealed room and considering a temperature above 80 degrees Celsius as 1 and a temperature below -50 degrees Celsius as 0. (The chance that a room moves from 80 degrees to -50 without your involvement is almost impossible.) The only, but significant, difference is that while moving between 80 and -50 degrees requires a lot of energy, for QUBIT to do the transition particle needs to be only targeted by microwave or light beam (and the same beam can even control multiple QUBITs simultaneously). Of course, the particles move along microscopic paths and at normal temperatures their movement is too quick and chaotic. Thus, to form QUBITs, the particles need to be “calmed down” until an almost absolute cessation of motion occurs, at a temperature (close to) zero Kelvin, or -273.15 degrees Celsius. This makes quantum computers relatively difficult to construct under normal conditions. As the idea of having something with temperature of minus 273 degrees on your desk is probably down right absurd.
Therefore, most quantum computers still work in closed laboratories where maintaining such a low temperature is possible and at least somewhat effective. A quantum laptop laid on the beach or on grass in a meadow doesn’t seem to be a very real idea. However, the fact that the construction of QUBIT requires “atypical” conditions does not exclude us all from the use of QC. Once someone is running a quantum computer, you can “borrow its computing power remotely“. All you have to do is submit a calculation request (along with inputs) from your computer via the Internet (or a private cloud), and the quantum administrator will include your calculation in the task queue. When comes the time for your calculation, the QC starts the script and tells you the result. After all, this was exactly how the big mainframes, where you also had to schedule some machine time, had been used first place.
Now that we know how QUBITs work physically, we need to point out one important contrast to conventional computers. QUBITs are real particles from real life, and although we can enforce at least elementary “obedience” upon them at low temperatures (and with some other measures), there is still a non-zero likelihood that some external influence (or accidental event) will deflect the energy of the particle and the ones turns to zero or the energy level got stuck somewhere between the zero level and the one level. (means, it is unclear whether the operation resulted in zero or one.) Therefore, logical QUBIT principle is used on top to prevent this phenomenon. This works in a way that physical QUBIT has several “siblings” on which the same operations are performed as on the initial QUBIT. The entire group of primary QUBIT and its physical siblings is called logical QUBIT. The value of the logical QUBIT is determined as the value that came out most often on physical QUBITs connected to the given logical QUBIT. That means that even if one of the 1000 physical QUBITs associated in a logical QUBIT is wrong (or its value cannot be detected), the other 999 still offer the same result and serve as a form of insurance. The probability that all 1000 would be wrong in the same direction at the same time is so low that it is completely negligible for the necessary calculations. In addition, if you repeat the calculation several times in sequence, you gain assurance that the quantum computer was not mistaken.
We explained how QUBITs look like. However, we still owe a substantial answer to how QC actually does the calculations. To do this, we need to clarify the concept of a reversible operation. This is a (mathematical) operation in which I can name the original inputs just from the result without the inputs ever being revealed to me. For example, the sum is not a reversible operation, because if you tell me that the sum of two numbers is 7, I cannot tell what two numbers you have added, there are infinitely many possibilities (e.g. -1000 + 1007 = 7). The classic computers we have on our desks today are programmed to do both reversible and irreversible operations. The tax for this is, as already mentioned, the storage needed for inputs and intermediate results. However, quantum computers are designed to perform only reversible operations. For example, multiplication -1 is a reversible operation because I do not need to know what the input was: if I see that the output is -10, I know that the input had to be 10 and only 10. For any other input I do not get -10 after multiplying by -1. Quantum computers thus calculate by taking input, executing a series (= quantum circuit) of reversible operations (also called quantum gates), and returning the result. However, since all operations are reversible, it is easy to chain operations into long sequences. It is also fast to check whether the result of the whole quantum circuit fits with the corresponding inputs. This allows a large number of operations to be performed without any memory requirement. Do you need to multiply two matrices, each with a million elements? No problem, QC can do it “out of its head” without having to make a note of anything. What is more, it does so about as fast as multiplying only one-hundred-elements-matrices with each other.
This specificity of the calculations makes the QC an excellent and ultra-fast solution for some types of calculations and, on the contrary, disadvantaged for some other (even trivial) operations. It is so because most common mathematical operations can be rewritten into a sequence of (several) reversible calculations (for example, if you want to calculate the product 100 x 10 you can take zero and add one hundred units 10 times to it (because +100 operation is reversible). For very large factors this would become obstacle itself rather than a help). So quantum computers are a bit, ehm, autistic. They do brilliant sophisticated things, but for some trivial things they are completely lost. Therefore, your homework from elementary school will probably never be counted on Quantum’s computer. Tasks where the power of QC significantly beats classic computers are tasks with either a huge number of things (e.g. stars, atoms, chemical reactions, …) or a very high number of repetitions of the same procedure (e.g. verifying if a number is not a prime number by trying to divide it by all lower primes). Thanks to the presence of complex numbers and something called superposition of particles, QCs also play a strong role in solving probability problems, predicting certain phenomena and sophisticated data analysis (QML).
The mass implementation of QC solutions is somewhat hampered by the technological development itself. Quantum computers will become really useful only when working with millions of physical QUBITs. With this quantity, it is possible to provide enough logical QUBITs that algorithms (like Shore, see below) need. However, since it must be maintained that QUBITs do not interact with each other and retain value for long enough time, technology is still struggling with making 10 million different particles to “work conscientiously for the common cause.” According to data from Jack D. Hidara’s current book, we are a still quite a few steps from this useful zone (now featuring few tens of logical qubits only):
A certain complication for the development of QC solutions is that in order to confirm the functionality of the algorithm on QC, one must (usually) perform a simulation of this process on a classical computer. However, since QUBIT needs approximately 4000 times more data space than 1 BIT on a conventional PC to store its states, a complete simulation of only 30 QUBITs would take up all of your Notebook memory. The thousands to millions of QUBITs that are really needed are out of question even with the world’s most supercomputers. To quickly compare, how much memory space (to simulate QC QUBITs) is needed, have a look at a neat overview from aforementioned book:
Sectors most affected by QC
We looked quite in detail at the difference between QC and their classic PC predecessors. However, we have not yet mentioned which areas of human life are most suitable for the introduction of QC. Some indication flashed with revealing that QCs have the mightiest power in tasks where CCs need to remember large data structures or where the complexity of classical computational algorithms is quadratic and higher. Probably the most straightforward impact of QC is on cryptography, or encryption. The safest ciphers currently rely on huge prime numbers that cannot be easily detected. On a classic computer, you need to try a large number of divisions (by smaller primes) to see if a number is a prime or not. The brute force of classical computers makes these ciphers unbeatable. You won’t be able to find the prime number you need while the password is in effect. However, QC is able to find, using Shor’s algorithm, prime factor decomposition much faster and thus break the (even today) super-safe ciphers with brute force. It is important to say that this is a double blow for cryptography. Not only can it break the current super-strong passwords, it also deprives cryptography of the way it resisted so far: Whenever current cryptographic keys became vulnerable to breakthroughs, the encryptors simply doubled their length and everything went beyond the old way again. However, the problem is that the computational complexity of QC key breaking only increases logarithmically, so even if a breaking of 10-digit password lasted a day, the 1000-digit break would only take 3 days and a million-digit password break would only last 6 days (approximate values to illustrate, in reality natural not decimal logarithm is applied). Thus, even a drastic jump from a 10-letter password to a million-letter password will not bring you much more protection.
The second area where the advent of quantum computers is unstoppable is chemistry, biophysics and pharmacy. Quantum computers are a great help in testing a large number of molecules in pharmacy. They are able to check much faster what combinations of substances achieve the desired effects, or which of the proteins have the greatest (statistical) predisposition to react in the way we need to achieve. Research in these areas will rapidly accelerate through QC, bringing more discoveries of active substances to medicine (and compound materials for industry).
A separate branch of QC future is the data analysis process that has “crawled” into all sectors of our company in the meantime. That’s also reason why I decided to popularize QC on this blog. Not only are quantum computers able to efficiently sort products (product recommenders) using Grover search, but especially the classification algorithms (Quantum Machine Learning) and QNN (quantum neural networks) are also progressing significantly. QC-based sampling algorithms are also very useful in statistics and data analysis, as unlike conventional quasi-coincidence randomness, quantum computers can generate real random numbers.
Although not yet confirmed by specific solutions, by the nature of the QC specifics, it is evident that quantum computers will also be used to manage the coordination of a large number of people and/or things. Working with huge matrices is a piece-of-cake for QC. It is thus clear that quantum computers will have a significant impact on (analysis and management of) telecommunications and social networks, transport or production. Similar models can be used for more detailed sociological and marketing analyses and simulations. Even early suggestions for using QC in high-frequency stock trading appeared, but I haven’t even noticed a comprehensive prototype in the expert literature yet. As the number of sectors into which QC “bites” is not small, it is advisable to consider the heading of the next paragraph:
Do we have to (re)learn to work with QC?
From the previous paragraph, you know that it is quite unlikely that we should (at least in the foreseeable future) replace our desktop computers with quantum computers. It is much more likely that, if we use quantum computers by chance, it will be remotely over the Internet (read as cloud). It is a bit analogous to operating a video drone, which also shoots video, just like a classic camera, but you also don’t fly in the air with the drone to actually shoot the video, but you control the drone remotely from the ground. Thus, a group of professions (such as QC engineer) will need to rise to keep quantum computers running, but most ordinary users will issue orders to quantum computers over distance.
That also means that you can take advantage of quantum computing, even if you may not understand quantum physics behind it. (Therefore, it is incomprehensible to me why most QC descriptions already kill readers on the second or third page of QC explanation by some ugly equations, discouraging them from reading on.) It is a bit like becoming a programmer: Wanna-be coders (probably still) have to go through Assembler, a binary programming language course, in which the tiny components of CC speak to each other. This programming language is called low-level, since it can be used directly at the lowest level (on BITs). Most operating systems of recent PC’s will not allow you to go “as deep” as issuing commands directly to micro components, as conventional processors have approximately 2 billion in action at the same time. (For better comprehension, hundreds of millions in area of your nail size). Giving orders directly to 2 billion parts is unthinkable for man, simply by design. Therefore, IT professionals have created an environment for us that is “high” above the level of the electronic circuits themselves. Similarly, with quantum computers: At the time of QC mass expansion, nobody will work directly on the quantum circuit level. High-level languages such as LIQui|>, Qiskit, Q#, Quipper, Cirq, Scaffold or ProjectQ will be used. Most of these languages are powered by Python, Java or C ++, so if you’re already working with data, switching to QC won’t be as big a jump as it may look.
The second important fact for the future is that QCs may not replace conventional computers, but rather complement them. Same way as more powerful graphics card, that you need to purchase in order to edit video or plot 3D architectural models. As mentioned before, Quantum computers will probably be controlled remotely, and how otherwise we would be able to control them than from a classic computer? From the nature of quantum computing, it does not make sense, e.g. to connect a monitor to the QC unit. Displaying the results of QC calculations is not very visually intuitive. (Often this is a multi-dimensional space that our 3D perception somehow does not swallow). Although it should be fairly acknowledged that it took decades to get to the monitors attached even to classical computers (Yes, you may not believe, but all the outputs were first on punch cards). So one day we may find a way to intuitively display QUBITs, maybe. For now, though, the results of the QC calculations are sent back to a standard computer that stores or displays them. Therefore, as far as we can see ahead, it looks more like a dual-horse-carriage QC + CC, rather than an invasion of stand-alone QC computers.
What does that mean for me?
If you have read this far, surely the thought of what all this means to me is whirling in your head. If we summarize the conclusions from different points of this blog into one summary, we shall arrive at:
a] Quantum computers will succeed in a relatively large number of industries for the future.
b] However, they are not a universal substitute for computers as we know them now. Most likely in the future, humanity will have systems that will be a combination of QC + CC.
c] If you are an ordinary office worker using a computer today, you may not need to relearn to work with QC again. However, if you happen to know how to use it, QC is a career opportunity for you. Assumption is it will be wanted in 5-7 years.
d] If you are a data analyst, researcher, or other profession that collects and evaluates large volumes of data (see industries above), you will have less of the choice. QC can indeed be a threat to you. Because a combination of QC + CC solutions is more than likely to appear in your working environment. If you don’t have “a clue” about QC principles, you can become less of an asset on the labor market.
e] Fortunately, the principles of quantum computers and their applications are easy to understand, even if you do not have a degree in Theoretical Physics or Mathematics. If you want to get ready for QC, I would suggest to start familiarizing with types of algorithms that are much faster on QC than on conventional computers. (However, you will need to study the different reversible operations that are possible on QC as prerequisite to understand how these algorithms work. This may not be necessary easy reading.) At the same time, I suggest to study integration of at least one of the aforementioned QC programming languages (e.g. Cirq) with Python.
For those really excited about the topic, I attach a few books where they can begin their knowledge-hunt journey. At the same time, I would like to remind each reader to leave feedback (via info@mocnedata.sk) about whether this blog helped you to understand what quantum computers are. Thank you in advance.
People who know me for a long time know that I can’t get much offended if labeled as bookworm. I really like to read (and do it a lot). However, only those closest to me know that I have every year resolution to read more than 10,000 pages of books in calendar year (beyond other than magazines, blogs and news articles.) To my pleasure, I have missed on this commitment only once in last 10 years. On the contrary, 2019 was one of my record reading years as I managed to read 39 books (and in middle of 5 more of them). The imaginary 10K pages bar was exceeded by thousand of the pages in past year. However, I don’t aim to bore you too much with quantities, this blog strives for a different goal.
I carefully consider the books I buy, as I refrain from running away from started reading (even if it later proves to be not the best choice). Paying respect to author’s efforts, I try to finish the book till its end. Of course, even master carpenter sometimes cuts his finger, but thanks to careful selection, the pleasant surprises are outstretching the disappointments. And that’s why I decided to share with you Best of My 2019 Reading List. (Filtered for books that fit TheMightyData topics)
Data For The People
Topics: Data, Data Analytics, Privacy
Without hesitation and long introductions: This book is one of the best books on data analytics (and its implications) I’ve read in the last decadeIt not only gives you an overview of the trends in data and their analytics that you should understand. It also offers interesting social insights on how to work with data to benefit our civilization. If you read between lines, you will also understand in which areas we still underestimate the impact of the data and we need to add it properly. Therefore, if you are involved in data analytics or processing, I simply recommend reading this book as soon as possible.
Many dare to drag sugar coat how artificial intelligence will affect your business. But did they also give you specific recommendations on where to start and how to achieve your first success with AI solutions in your particular situation? Your answer may not surprise me. There is plethora of Oracles moving in mute AI waters. This book, in contrast, provides concrete examples of how to apply advanced data analytics and individual forms of artificial intelligence to Marketing and Product Management. Very unique, thus the more valuable cookbook and inspiration for almost every employee in the company.
Are you trying to come up with a concept or solution? Did you get a task you don’t know how to grab? Did you get burned on a project that seemed straightforward at first sight. Then you stand in front of a book that will guide you through how to design (and realize) ideas so that they are really useful and deliver what is expected of them. In short to be Meaningful, indeed.
Finding a good book on Artificial Intelligence and its impact on society is really difficult feat. Topic is intensely hyped and real AI awareness is more pretended than achieved. Thus it is of immense value when someone truly knowledgeable explains the nature of Artificial Intelligence and its social impact, step by step. Kai Fu Lee is such a person. Moreover, as he comes from the Chinese environment first place, his views depict true country capabilities (and weak points) and goals of AI in China to the reader with neither Chinese shine nor Western propaganda. He serves valuable insights to why China’s development is moving the very direction and pace it takes. Let me, thus, express my forecast that Lee’s book will be a mandatory reading for the next decade for anyone who is aware artificial intelligence advent.
Have you ever stumbled upon a book, you said, “Oh, God, if I had seen you before?” A few quarters back I led a project that sought to build a marketplace for services. Despite the fact that the project was full of experienced people, we were very anxious (and now I know that we have) made many serious mistakes. The Platform Revolution book intriguingly summarizes the principles of such E-commerce marketplaces and explains how to avoid the most common failures of this type of business. So if you are also “up to” to an E-commerce project, I recommend you reading this book.
Sometimes there is no need to tip-toe around hot pot. The reason to read this book is very simple. As is it is to frame target audience for this book. If you have the happen to have responsibility for getting a business (or process) into higher gear, be sure to read Blitz Scaling. Moreover, it is also interesting read for ordinary mortal who wants to understand which services around us will grow steeply in the near future and which will curb instead.
As the saying goes: After the war everyone is a general.” In economy this maxim turns into small variation of “After the crisis everyone is an economic analyst who predicted it”. However, what should you do if you work among central bankers (and others who run the financial markets), you see an upcoming problem, but you are in a brutal minority. Well, if you are a Mohamed A. El-Erian (manager managing perhaps the largest portfolio of mutual funds), you will write a good book about it so that you open the eyes of many others. If you are eager to understand why another crisis is in baking up and who to blame for it this time, invest a few hours of your time in reading this book.
Did you read Nick Bostrom’s 21st Century Bible? Did you get interested and would like to expand your horizon even further? Then I have good news for you. Tom Chivers took the effort not only to write some sort of free continuation (and conclusions extension) brought to Bostrom. He has also worked out a sort of summarizing layer that will give you a better understanding (of Bostrom himself and) why most people who understanding the AI trends are more cautious pessimists than current development enthusiasts. As the title of the book itself suggests, it is not necessary to take it personally. That AI (apparently) will replace your work is no less or more certain than it replacing your neighbor’s work. But how to look despite these prospects with joy into future can be found in this very book.
I admit, this recommendation is a little consequence of me living in Germany for last years. But the reason why I recommend you read this book is that in, literally, few hours you will embrace the whole relevant European context. You will understand why Germany is Europe’s driving force today, even though most of history it was not. You will understand why a third of Berlin spoke French even before Napoleon arrived, how the Reformation was related to the advent of Hitler, and why, in fact, East Germany was a Cinderella whom many were still afraid of. This book is an instant extension of your cultural IQ. Even if you do not live in Germany neither you are a history fan, I still urge you to read this subtle book.
You may laugh loud, but I would criticize this book for just one thing: it is too short. Turning The Flywheel is actually one of the shortest books I’ve read. (only 48 pages). But the shorter the print, the more intense her message is. Even in such a limited space this booklet offers, you will find instructions on how to make your business or teamwork self-propelling. In other words, how to do things that in return synergically help to keep themselves well above average successful. If I wanted to be too simplistic: How to do ingenious things that spin on the flywheel yourself while you take a rest.
I had the chance to meet Tom Davenport in person (at a conference in London), and I have always been eager to swallow his books because I consider them to be a high-quality summary of important data analytics principles. In building analytical teams throughout my career I often gained inspiration. However, to be honest, his latest book was personally a bit disappointing to me. Maybe this is my bias (and that’s why perhaps a little controversial item in this reading suggestion). In some chapters I felt that I was not sure if the recommendations were based on real experience or that someone only “tipped” them to Tom. However, the book also has high-quality passages, so take the chance on it (and let me know how it turned out for you).
Skepticism about artificial intelligence’s negative impact on jobs is recently emerging quite a bit. There are relatively few books and articles that would compensate for this “bad mood” about AI’s role in the labor market. That is why HUMAN + MACHINE has been a jewel of recent days. It offers a counterbalance to the skeptical view of AI’s future and gives substantial hope for the masses. It strives to show how (realistically) machines and people will work together to fulfill the tasks & goals today done solely by humans. Thus, if you (want to) believe in good, this is a great stepping stone for you.
Have you ever wondered why so many companies went bankrupt and even grandiose business plans fail? Does the waiter service make you cry or do you condemn fraudulent market practices? Simon Simek offers a very interesting look at this topic. Book will gradually guide you through realization that most companies consider business just a way from one mile-stone to another, resembling rather a sport event or a game session than a long-term strategy. As you read, you gradually understand that the human life, society, business (and many other things) has been there, and will stay, even once we individually pass out. It is a form of “indefinite game” in which most KPIs and short-term approaches are not only ineffective but down right counterproductive. This book is vital read for anyone who wants to do business honestly, lead people or live a meaningful life. The script is not necessarily for the masses. But therefore much more inspiring for those who do not seek shortcuts and who search recipe to do things properly.
Do you want to know why people “piss you off”? Are you desperate in dealing with certain person? Then be sure to read this book. You may have encountered MBTI, DISC, or other tools to attribute personality profiles to individuals. Knowing what kind of different people types are around and how to best handle them is really helpful. (and often stress relieving for your life) The book Surrounded by idiots at first glance uses “just another” Carl G. Jung’s color methodology, but it serves it in a very, really very understandable language, opening up the possibility to grasp human differences and (especially how) to use them in life of the ordinary man. That’s why I highly recommend this book to all of us.
I kept on suggesting the books in past. However, this year I would like to add one novelty beyond history. I will also reveal something from my future letter for 2020. These books are already daringly looking at me from the shelf (and they will come into play soon):
Human Compatible: Artificial Intelligence and the Problem of Control
Topics: Artificial Intelligence
If you have already read (or even programmed) artificial intelligence, you probably have realized that the advent of artificial intelligence carries many, for mankind even existential, hitches. This book zooms on some of them and gives a clear report on whether and to what extent we already are ready to bound human and robot lives together.
Edward Snowden’s story will be familiar to you at least marginally. However, his mission is often narrowed to a single notion of US intelligence and security services confidential information disclosure. Subsequently, he lived a James Bond-like life: in run, hide, dwelling in various embassies. However, more interesting is Snowden’s life before the famous whistle-blowing event as well as the motives that led him to do so. Promising read guaranteed.
He was the youngest world champion in chess and remained the longest serving one ever. Garry Kasparov. When asked about secret recipe for that, he joked he had been washing his teeth every night and drinking tonic before each game. But it was just his replica in the spirit of “for silly question, equally solid answer”. When you let him freely talk about his perception of life and decision making, suddenly you fail to keep the notes of all maxims he serves. If Simon Simek sees life as an episode in the eternal Game, this book is like the magnetic counter-pole. Thus, if you want to find out who of these two great authors have come closer to (your) reality, you will not regret to engage in reading this book as well.
We have voluntarily let observers into our lives. Social networks and the Web generally collect our ideas, preferences and personal information, combine them to create much more interesting, aggregated data. Some conclusions are truly amazing and sharply helpful. Their only mistake is that we don’t own them. Yes, it’s the perfect digital “about us without us”. Most of us are shrugging our shoulders, as that’s just the way it is. But does it really have to? And could it possibly be completely the other way around? What changes in digital ownership (standards and laws) shall we implement so that we are not fenced completely out of the game?
They are Cinderellas. Most people look at them with disdain. They combine slightly lower comfort with more effort. And this is, let’s face it, not exactly the most lucrative combination you can think of. However, they are more spatially concise and thus more practical as well. And if you add electricity to them, that’s already another level.
Have you guessed what the previous mysterious paragraph referred to? Yes, we’re talking about scooters, my favorite vehicle. Berlin is a city strongly inclined to cycle traffic. Over 500,000 people are estimated to travel here every morning on various forms of (human-powered) wheels . Yes, you read correctly: 500,000 people every morning. Berlin hosts incredible 620 km of cycle paths or sidewalks built within the city. What is more, in Berlin, as in one of the few cities around the world, bicycles can even be taken to the subway. Simply a cycling paradise on Earth.
Scooter metamorphosis
But back to scooters: Two years back, when I started riding my scooter around streets of Berlin, I met with general amazement and sarcasm. Some of the “real cyclists” have even mocked “if they didn’t have pedals in the bike shop when I was there.” (the fact that the funny cyclist with his pedals did not catch up with me ever after that day, I leave aside for now). However, the situation around scooters has changed significantly over the last 18 months. Electric scooters entered the game.
The austerely designed scooters, equipped with an engine, can go over 20 km/h. Their main advantage is that you do not need a driver’s license to rent them, so they can be borrowed by anyone, whether you are a tourist or a local citizen. This is probably just one of the reasons why literally a “scooter war” is raging in the biggest German cities. According to independent estimates, more than 4800 electric scooters operate in Berlin alone. To put it in context, there are approximately 4,000 streets in Berlin, so there is already more than one electric scooter per each street street today. The purpose of this blog, though, is not to delve into the comparison of market shares or the quality bench-marking of individual services; (this is done well here) Electric scooters conceal one more interesting surprise.
The combination of their considerable number and the fact that each scooter is equipped with a number of sensors create a very interesting data sets for many (not just scooter operation relevant) Data Science analyses. This, at first sight inconspicuous, corner of data analytics even made it last month to its own topic of AI Meetup, here in Berlin. Hence, I can give you first hand report on what you can actually analyze around scooters.
When and where to place them
I remember a little embarrassing start of bike-sharing application in my home town, where initially the problem was mainly that bicycles were not where they were in demand, and on the contrary, they parked abundantly in places nobody desired them to be. The main reason for such a disparity is fact that the flow of traffic in the city is not symmetrical. If a taxi driver takes you in the evening from the center to the suburbs, it would be naive for him/her to stay in the suburbs waiting (in order to maximize fuel efficiency) to drive someone in the opposite direction at night. Obviously (s)he would have to wait until morning when everyone was back in town. However, as time is money, it is better to take the car “at own expense” back to the center, where it easily gets another order. What we consider to be quite logical for taxis, for scooters, takes a completely different dimension. The scooter cannot (for the time being) move itself and therefore it is necessary (several times a day) to transport scooters between individual stations when operating such a sharing services. And here comes the first data science opportunity that needs to be resolved: “When and where should scooters be relocated so that the cost of relocating them is covered by additional revenue from the new location where you put them?”
The figure above illustrates how one of the scooter services in Berlin took up this task. They have created a demand map based on their driving history data. However, demand is not in frequency measure, but directly in revenue value. A different shade of points indicates how much revenue a scooter (on average) achieves when starting from that very location. Therefore, it is necessary to pair up places with pale color with closely neighboring dark points. Add a radius that a person is willing to go to fetch a free scooter and you have a preliminary plan on how to move them. That it really works like that I saw one evening with my bare eyes: The delivery of the one of the companies stopped at a place where there were suspiciously too many scooters, the driver got off and put some of the scooters on the hull, ordering the other in line. And off he was to a better place for them.
New energy influx
Scooters need to be “visited” not only because of their location, but also because they are electric. If you rent a car, you are obliged to refuel it. However, you rent a scooter for a few minutes and you do not have a place to refuel it with electricity. (Although there are first attempts to motivate last-in-the-day users to take the scooter home and recharge it overnight.) In addition to relocation logistics, scooters’ batteries also need to be replaced. (Which is faster than recharging them on site.) Of course, it would be ideal if the scooter transfer could be combined with a battery change, but the battery would also run out of scooters that are in optimal locations or where there are enough other scooters, so one less charged piece can quietly wait there until the next visit of the charging patrol. How long routes do people usually make from the place where the scooter is parked? What is in reality a critically low battery state for that location? And what recharging the battery at this stage will mean for the overall battery life in the future? These are just some of the considerations that a data team planning to replace batteries needs to count into overall optimization decision.
User profiles and micro products
As with any service provider, for scooters, the main goal is to get to know their users. Because if you do not want to bite you nails every morning, with worries if you earn enough today, you need to know the habits of your clients. Hence, a separate topic of Data Science help is client segmentation with assignment of expectations and commercial value for each of the segments. A person who rides your scooter to work has a totally different customer value than a tourist who has tried your service out of the curiosity. On the other hand, a regular user will be much less tolerant of a missing or damaged scooter near his home. And since competition is numerous, any disappointment of regular clients can easily lead to their loss. It is, thus, super important to properly design the micro products (weekly ticket, offer of the day, …) to keep the client loyal.
When to see the doctor
Like any thing that does not have one owner, the biggest Achilles heel of shared scooters is that they have many users, but none of the scooter-caring “owner”. In addition, the scooters have mostly subtle (less than 12 inch) wheels that get tough times when the scooter is highly busy. Although the feedback from experienced defects gradually helps to boost the lifetime of individual scooter models (by adjusting their design), most of the current riding units will not live for more than 14 months; In really busy locations this value can fall as low as 10 months. Even though this may seem a complication especially for scooter companies at first glance, in real life it is more of an inconvenience for the end users. Imagine using a scooter to commute to work. You see on the map that some piece is available, so you can count on it on this mode of transport for your way to work . However, when you come to a scooter, you find that it is broken and you are left in limbo how to meet your first meeting starting time. Too bad. Now even discussing the scenario that your scooter damages within your ride, exposing you to real life-threatening moments.
Therefore, one of the key topics of data analytics in this industry is fault prediction (technically called predictive maintenance). If historical failure data are correctly recorded, it is possible to see which factors of use increase or decrease the failure likelihood. At the same time, the company has complete information on what kind of usage are currently undamaged units subjected to, it can identify specific vehicles that are likely to break down in the coming days/hours. Since the individual scooters (as discussed above) need to be relocated regularly, the by next relocation schedule the actual malfunctioning can be prevented by replacing the soon-to-fail piece with a new one. This significantly reduces the risk of inconvenience to final clients and also prevents injuries. All this, though, requires one more interesting analysis, which we will turn to in the next paragraph.
Quo vadis
At first hearing, it seemed to me as an unnecessary academic exercise. But the more I had the chance to discuss it with the insiders, the more it made sense to me. Yes, we are talking about profiling roads ridden by scooters. As shocks are an unwelcome “pleasure” for both fine electronics and wheels, knowing how much time the scooter has traveled on which surface has been an important factor in predicting wear. Likewise, when did the scooter went downhill or up the hill, as it strains the physical parts of the scooter more than on the flat ride profile. Last but not least, it is important to know where the ride happened also due to cycling lanes coverage or risk of accidents in individual sections. Thus, the most advanced analytical teams extend map data with layers of data such as which streets have cobbles, what slope a given street has, or how many of our own service (and other road accidents, e.g. by cyclists) have taken place at each location. Initially, this data is likely to be used for internal scooter operation and technical improvement purposes mainly. However, later a different price per kilometer is also possible, depending on where exactly did the scooter drive through, to take into account wear (and indirectly motivate people to drive on more gentle surfaces.)
Try on your own, maybe …
If you are interested in scooter data, there are already several Open data sets that are freely available. So far not directly from Berlin, but apparently for start that does not matter that much. Thus, if this article have “got you started” to analyze scooter data, try one of the above tasks on the Open data sources on your own. Maybe you will be get attracted to work in one of the scooter companies. Or at least it pokes you to try some e-scooter service first place.
 Before I fulfill the above-mentioned promise of initiating you into testing accuracy, please allow me two short, personal notes. I have had this blog in progress for several weeks by now, but this week’s statement by the Slovak government that it wants to test the entire Slovak population (by antigen tests) has pushed me to finish it quickly. I believe that the information from blog(s like this) will be important for the discourse of the coming days (and one’s decision on whether to take part or not in this population test voluntarily). The second personal point is that today it is exactly 10 years since I started writing blogs! Unfortunately, there was no cake with candles. But as you can see, I celebrated blogging anniversary with, ehm, blog work. I can’t promise to keep myself blogging for another 10 years. But I’ll do my very best to make this (295th) blog, as interesting and inspiring a read, as more than half a million unique views of my previous blogs were. Now back to the tests.
Before I fulfill the above-mentioned promise of initiating you into testing accuracy, please allow me two short, personal notes. I have had this blog in progress for several weeks by now, but this week’s statement by the Slovak government that it wants to test the entire Slovak population (by antigen tests) has pushed me to finish it quickly. I believe that the information from blog(s like this) will be important for the discourse of the coming days (and one’s decision on whether to take part or not in this population test voluntarily). The second personal point is that today it is exactly 10 years since I started writing blogs! Unfortunately, there was no cake with candles. But as you can see, I celebrated blogging anniversary with, ehm, blog work. I can’t promise to keep myself blogging for another 10 years. But I’ll do my very best to make this (295th) blog, as interesting and inspiring a read, as more than half a million unique views of my previous blogs were. Now back to the tests.
 So what? Do you already have your favorite of the 4 metrics listed? If you think it is enough to have a high overall accuracy, you are dangerously wrong. Try the following example: You have 2 lie detectors, both of which are 90% successful in overall. However, detector A has the remaining 10% on top of the successful readings in the FP box and detector B has them in the FN box. In terms of overall success, you should not care about what you want to be examined on. However, the essential difference between A and B is: Whenever detector A is unsure, it will identify you as guilty, while B whenever it gets unsure will label you as innocent. So what? Still don’t care which one to take?
So what? Do you already have your favorite of the 4 metrics listed? If you think it is enough to have a high overall accuracy, you are dangerously wrong. Try the following example: You have 2 lie detectors, both of which are 90% successful in overall. However, detector A has the remaining 10% on top of the successful readings in the FP box and detector B has them in the FN box. In terms of overall success, you should not care about what you want to be examined on. However, the essential difference between A and B is: Whenever detector A is unsure, it will identify you as guilty, while B whenever it gets unsure will label you as innocent. So what? Still don’t care which one to take?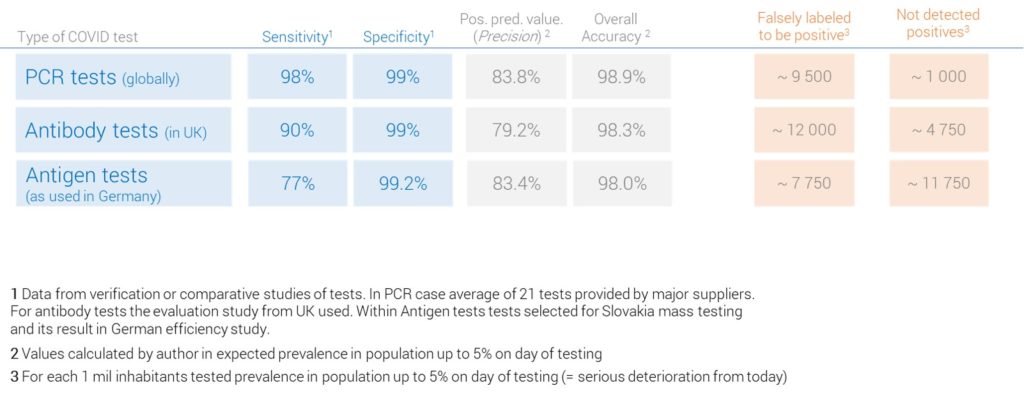
 Competing In The Age of AI
Competing In The Age of AI
 Dark Data
Dark Data


 DIEŤA 44
DIEŤA 44
 Let me make one important point before describing the sectors that will receive the worst ‘slap on their face’ during this epidemic. Many people may (and will) lose their jobs during this crisis. Possibly, even in companies from industries completely different to ones I mention in this article. However, this is due to the fact that any (economic) crisis is also a sieve through which companies, built only for good times, do not make it to swim through. As my boss typically said: “When the tide recedes, we can see who had a swimsuit and who was swimming naked.” Running long-run business on low margin can work in all-is-booming times. In economy shocks like now, this will, literally, break your neck. After all, to withstand two-month sales shortfall means to have a reserve of merely 15%. So let me ask a slightly cheeky question: “How responsibly does the management lead the company if it does not have a “pillow” (or the possibility to bridge revenues with a short-term loan) for at least the given 10-15% of Sales?” Thus, yes, anyone can go bust within a crisis. However, in the following paragraphs, I would like to address those cases who are even not to be blames. In other words, those who might end up in sorrow corner (almost) no matter what they choose to do differently. The club of, sadly, innocent but in deep s….. (struggle :).
Let me make one important point before describing the sectors that will receive the worst ‘slap on their face’ during this epidemic. Many people may (and will) lose their jobs during this crisis. Possibly, even in companies from industries completely different to ones I mention in this article. However, this is due to the fact that any (economic) crisis is also a sieve through which companies, built only for good times, do not make it to swim through. As my boss typically said: “When the tide recedes, we can see who had a swimsuit and who was swimming naked.” Running long-run business on low margin can work in all-is-booming times. In economy shocks like now, this will, literally, break your neck. After all, to withstand two-month sales shortfall means to have a reserve of merely 15%. So let me ask a slightly cheeky question: “How responsibly does the management lead the company if it does not have a “pillow” (or the possibility to bridge revenues with a short-term loan) for at least the given 10-15% of Sales?” Thus, yes, anyone can go bust within a crisis. However, in the following paragraphs, I would like to address those cases who are even not to be blames. In other words, those who might end up in sorrow corner (almost) no matter what they choose to do differently. The club of, sadly, innocent but in deep s….. (struggle :). As you will read on in a moment, there are certain commonalities among the individual “victims” of the COVID-19 crisis. However, in order for our discussion to have a proper turn, let’s depict a few concrete examples:
As you will read on in a moment, there are certain commonalities among the individual “victims” of the COVID-19 crisis. However, in order for our discussion to have a proper turn, let’s depict a few concrete examples: As I have already indicated, the destruction brought by COVID-19 is led by certain common features. The first one is represented by what the direct consequences of this epidemic are. As we described in the
As I have already indicated, the destruction brought by COVID-19 is led by certain common features. The first one is represented by what the direct consequences of this epidemic are. As we described in the  In ancient Greece, the square root was defined (by Pythagoras) as the diagonal of the rectangle (e.g. the square root of 5 is the diagonal of the rectangle with sides of 1 and 2) and each line ( even diagonal) must be larger than zero. This burden has been on our shoulders for more than 2,000 years, until someone said: What if we imagined an virtual (third) dimension in which any 2D object could be rotated by some angle. Like an arrow drawn from the center out on the right page of a book with thin, translucent leaves. As you turn the page of the book, the same arrow suddenly – though it has not changed at all – points in the opposite direction (from center to left). If we take the arrow as a shift on the map by 1 length unit from point A to B, after reversing suddenly we have a shift of -1 (that is the same length, but in the opposite direction). Somewhat analogically, a diagonal of a square root of -1 can be formed. It is the angle of rotation in the imaginary third dimension that is the essence of complex numbers. In order to make it easier to calculate, a unit of rotation (= a quarter of circle rotation) has been chosen, which (after some trigonometric transformation) is labeled as a lower case “i”.
In ancient Greece, the square root was defined (by Pythagoras) as the diagonal of the rectangle (e.g. the square root of 5 is the diagonal of the rectangle with sides of 1 and 2) and each line ( even diagonal) must be larger than zero. This burden has been on our shoulders for more than 2,000 years, until someone said: What if we imagined an virtual (third) dimension in which any 2D object could be rotated by some angle. Like an arrow drawn from the center out on the right page of a book with thin, translucent leaves. As you turn the page of the book, the same arrow suddenly – though it has not changed at all – points in the opposite direction (from center to left). If we take the arrow as a shift on the map by 1 length unit from point A to B, after reversing suddenly we have a shift of -1 (that is the same length, but in the opposite direction). Somewhat analogically, a diagonal of a square root of -1 can be formed. It is the angle of rotation in the imaginary third dimension that is the essence of complex numbers. In order to make it easier to calculate, a unit of rotation (= a quarter of circle rotation) has been chosen, which (after some trigonometric transformation) is labeled as a lower case “i”.
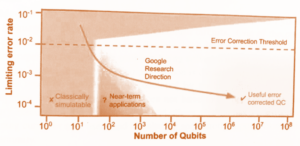

 Data For The People
Data For The People
 Meaningful: The Story of Ideas That Fly
Meaningful: The Story of Ideas That Fly
 Platform revolution
Platform revolution
 The Only Game In Town
The Only Game In Town
 The Shortest History Of Germany
The Shortest History Of Germany
 The AI Advantage
The AI Advantage
 The Infinite Game
The Infinite Game
 Human Compatible: Artificial Intelligence and the Problem of Control
Human Compatible: Artificial Intelligence and the Problem of Control
 How Life Imitates Chess
How Life Imitates Chess

 As with any service provider, for scooters, the main goal is to get to know their users. Because if you do not want to bite you nails every morning, with worries if you earn enough today, you need to know the habits of your clients. Hence, a separate topic of Data Science help is client segmentation with assignment of expectations and commercial value for each of the segments. A person who rides your scooter to work has a totally different customer value than a tourist who has tried your service out of the curiosity. On the other hand, a regular user will be much less tolerant of a missing or damaged scooter near his home. And since competition is numerous, any disappointment of regular clients can easily lead to their loss. It is, thus, super important to properly design the micro products (weekly ticket, offer of the day, …) to keep the client loyal.
As with any service provider, for scooters, the main goal is to get to know their users. Because if you do not want to bite you nails every morning, with worries if you earn enough today, you need to know the habits of your clients. Hence, a separate topic of Data Science help is client segmentation with assignment of expectations and commercial value for each of the segments. A person who rides your scooter to work has a totally different customer value than a tourist who has tried your service out of the curiosity. On the other hand, a regular user will be much less tolerant of a missing or damaged scooter near his home. And since competition is numerous, any disappointment of regular clients can easily lead to their loss. It is, thus, super important to properly design the micro products (weekly ticket, offer of the day, …) to keep the client loyal. Therefore, one of the key topics of data analytics in this industry is fault prediction (technically called predictive maintenance). If historical failure data are correctly recorded, it is possible to see which factors of use increase or decrease the failure likelihood. At the same time, the company has complete information on what kind of usage are currently undamaged units subjected to, it can identify specific vehicles that are likely to break down in the coming days/hours. Since the individual scooters (as discussed above) need to be relocated regularly, the by next relocation schedule the actual malfunctioning can be prevented by replacing the soon-to-fail piece with a new one. This significantly reduces the risk of inconvenience to final clients and also prevents injuries. All this, though, requires one more interesting analysis, which we will turn to in the next paragraph.
Therefore, one of the key topics of data analytics in this industry is fault prediction (technically called predictive maintenance). If historical failure data are correctly recorded, it is possible to see which factors of use increase or decrease the failure likelihood. At the same time, the company has complete information on what kind of usage are currently undamaged units subjected to, it can identify specific vehicles that are likely to break down in the coming days/hours. Since the individual scooters (as discussed above) need to be relocated regularly, the by next relocation schedule the actual malfunctioning can be prevented by replacing the soon-to-fail piece with a new one. This significantly reduces the risk of inconvenience to final clients and also prevents injuries. All this, though, requires one more interesting analysis, which we will turn to in the next paragraph. At first hearing, it seemed to me as an unnecessary academic exercise. But the more I had the chance to discuss it with the insiders, the more it made sense to me. Yes, we are talking about profiling roads ridden by scooters. As shocks are an unwelcome “pleasure” for both fine electronics and wheels, knowing how much time the scooter has traveled on which surface has been an important factor in predicting wear. Likewise, when did the scooter went downhill or up the hill, as it strains the physical parts of the scooter more than on the flat ride profile. Last but not least, it is important to know where the ride happened also due to cycling lanes coverage or risk of accidents in individual sections. Thus, the most advanced analytical teams extend map data with layers of data such as which streets have cobbles, what slope a given street has, or how many of our own service (and other road accidents, e.g. by cyclists) have taken place at each location. Initially, this data is likely to be used for internal scooter operation and technical improvement purposes mainly. However, later a different price per kilometer is also possible, depending on where exactly did the scooter drive through, to take into account wear (and indirectly motivate people to drive on more gentle surfaces.)
At first hearing, it seemed to me as an unnecessary academic exercise. But the more I had the chance to discuss it with the insiders, the more it made sense to me. Yes, we are talking about profiling roads ridden by scooters. As shocks are an unwelcome “pleasure” for both fine electronics and wheels, knowing how much time the scooter has traveled on which surface has been an important factor in predicting wear. Likewise, when did the scooter went downhill or up the hill, as it strains the physical parts of the scooter more than on the flat ride profile. Last but not least, it is important to know where the ride happened also due to cycling lanes coverage or risk of accidents in individual sections. Thus, the most advanced analytical teams extend map data with layers of data such as which streets have cobbles, what slope a given street has, or how many of our own service (and other road accidents, e.g. by cyclists) have taken place at each location. Initially, this data is likely to be used for internal scooter operation and technical improvement purposes mainly. However, later a different price per kilometer is also possible, depending on where exactly did the scooter drive through, to take into account wear (and indirectly motivate people to drive on more gentle surfaces.)